| Unity3D Shader系列之Compute Shader基础及图像灰度化 | 您所在的位置:网站首页 › Unity3d图片挖洞 › Unity3D Shader系列之Compute Shader基础及图像灰度化 |
Unity3D Shader系列之Compute Shader基础及图像灰度化
|
目录
1.什么是Compute Shader2.Compute Shader语法2.1 #pragma kernel2.2 Compute Shader中的变量2.2.1 标量2.2.2 向量2.2.3 矩阵(matrix)2.2.4 数组2.2.5 StructuredBuffer2.2.6 Texture
2.3 numthreads与Dispatch2.3.1 numthreads2.3.2 线程为什么要分组2.3.3 numthreads中的xyz值何时最优2.3.4 Dispatch
2.4 SV_DispatchThreadID
3. Compute Shader灰度化图像4 参考文章
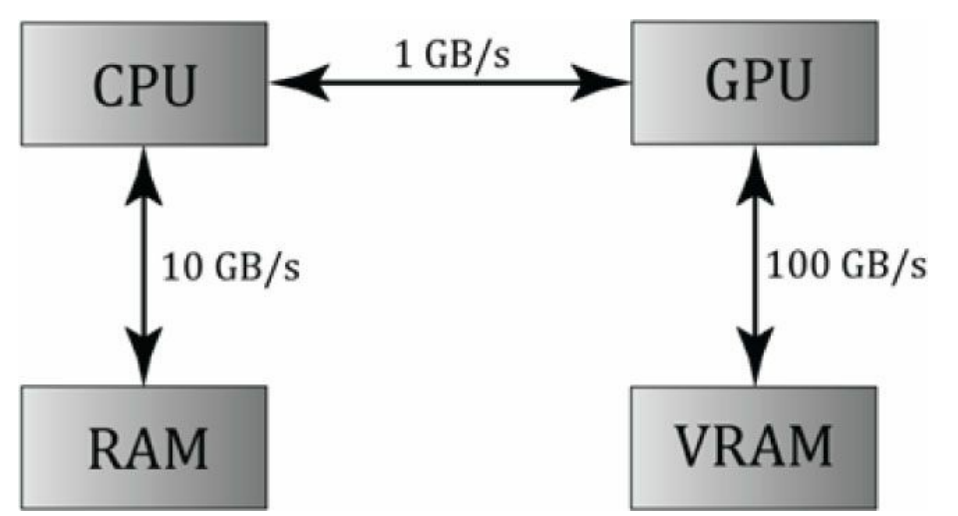
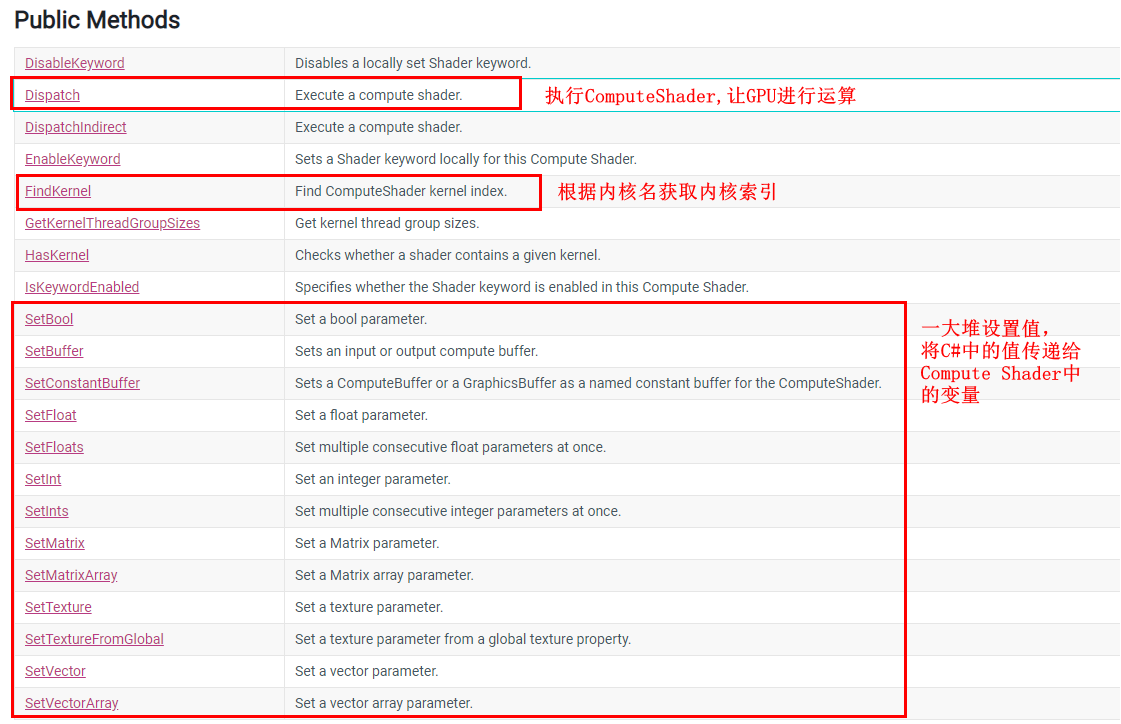
前两篇我们分别用OpenCV for Unity和片元着色器实现了图像灰度化的功能,今天我们来看看使用Compute Shader实现图像灰度化的功能。 1.什么是Compute Shader定义 Compute Shader也是Shader中的一种,也运行在GPU上。它和我们平时说的顶点、片元着色器不同地方在于,Compute Shader不经过渲染流水线,而是用于通用计算。什么是通用计算呢?就是把之前在CPU的计算挪到GPU这边来。基于GPU强大的并行计算能力,与通过CPU计算相比能极大地缩短计算时间。使用GPU进行通用计算又叫GPGPU(General Purpose GPU Programming)编程。 适用场景 可以并行计算的地方,如图片的处理,视频编码。 我们这里想使用Compute Shader对图片进行灰度化。原因有二,①是图片上各个像素点灰度计算互不干扰,可以利用GPU的强大并行计算能力;②是通过GPU计算生成的图片可以不用再传回CPU而直接层递到屏幕,这也是个提升效率的地方。 性能瓶颈 如图,CPU和GPU之间的数据传输是瓶颈。 如图,首先创建一个Compute Shader。 用于定义内核,一个Compute Shader至少要有一个内核。内核其实就是下面定义的方法名,我们可以在CPU端命令GPU执行这个内核(ComputeShader.Dispatch,后面会讲到)。 #pragma kernel CSMain上面这句代码就表示CSMain这个方法是一个内核。 在c#这边,我们通过使用ComputeShader.FindKernel去持有并记录到对应内核的索引值,以后向GPU传递数据时都需要传递它。 FindKernel的参数只有一个,即Compute Shader中内核名(由#pragma kernal指定的),返回值为该内核的索引。 // 参数为内核名(由#pragma kernal指定的),返回值为该内核的索引。 int kernal = cs.FindKernel("CSMain"); 2.2 Compute Shader中的变量Compute Shader语言是HLSL,所以HLSL支持的变量其都支持。 可去微软官方文档查看。 注:标量到数组部分摘自文章《DirectX11–HLSL语法入门》 2.2.1 标量 类型描述bool32位整数值用于存放逻辑值true和falseint32位有符号整数uint32位无符号整数half16位浮点数(仅提供用于向后兼容)float32位浮点数double64位浮点数 2.2.2 向量向量类型可以支持2到4个同类元素。 3种申明向量的方式。 1.使用类似模板的形式来描述 vector vec1; // 向量vec1包含4个float元素 vector vec2; // 向量vec2包含2个int元素2.直接在基本类型后面加上数字 float4 vec1; // 向量vec1包含4个float元素 int3 vec2; // 向量vec2包含3个int元素3.使用vector本身则表示为一种包含4个float元素的类型** vector vec1; // 向量vec1包含4个float元素向量的初始化。 float2 vec0 = {0.0f, 1.0f}; float3 vec1 = float3(0.0f, 0.1f, 0.2f); float4 vec2 = float4(vec1, 1.0f);向量的使用与赋值。 向量的第1到第4个元素既可以用x, y, z, w来表示,也可以用r, g, b, a来表示。除此之外,还可以用索引的方式来访问。下面展示了向量的取值和访问方式: float4 vec0 = {1.0f, 2.0f, 3.0f, 0.0f}; float f0 = vec0.x; // 1.0f float f1 = vec0.g; // 2.0f float f2 = vec0[2]; // 3.0f vec0.a = 4.0f; // 4.0f我们还可以使用swizzles的方式来进行赋值,可以一次性提供多个分量进行赋值操作,这些分量的名称可以重复出现: float4 vec0 = {1.0f, 2.0f, 3.0f, 4.0f}; float3 vec1 = vec0.xyz; // (1.0f, 2.0f, 3.0f) float2 vec2 = vec0.rg; // (1.0f, 2.0f) float4 vec3 = vec0.zzxy; // (4.0f, 4.0f, 1.0f, 2.0f) vec3.wxyz = vec3; // (2.0f, 4.0f, 4.0f, 1.0f) vec3.yw = ve1.zz; // (2.0f, 3.0f, 4.0f, 3.0f) 2.2.3 矩阵(matrix)矩阵有如下类型(以float为例): float1x1 float1x2 float1x3 float1x4 float2x1 float2x2 float2x3 float2x4 float3x1 float3x2 float3x3 float3x4 float4x1 float4x2 float4x3 float4x4此外,我们也可以使用类似模板的形式来描述: matrix mat1; // float2x2而单独的matrix类型的变量实际上可以看做是一个包含了4个vector向量的类型,即包含16个float类型的变量。matrix本身也可以写成float4x4: matrix mat1; // float4x4矩阵的初始化方式如下: float2x2 mat1 = { 1.0f, 2.0f, // 第一行 3.0f, 4.0f // 第二行 }; float3x3 TBN = float3x3(T, B, N); // T, B, N都是float3矩阵的取值方式如下: matrix M; // ... float f0 = M._m00; // 第一行第一列元素(索引从0开始) float f1 = M._12; // 第一行第二列元素(索引从1开始) float f2 = M[0][1]; // 第一行第二列元素(索引从0开始) float4 f3 = M._11_12; // Swizzles矩阵的赋值方式如下: matrix M; vector v = {1.0f, 2.0f, 3.0f, 4.0f}; // ... M[0] = v; // 矩阵的第一行被赋值为向量v M._m11 = v[0]; // 等价于M[1][1] = v[0];和M._22 = v[0]; M._12_21 = M._21_12; // 交换M[0][1]和M[1][0]无论是向量还是矩阵,乘法运算符都是用于对每个分量进行相乘,例如: float4 vec0 = 2.0f * float4(1.0f, 2.0f, 3.0f, 4.0f); //(2.0f, 4.0f, 6.0f, 8.0f) float4 vec1 = vec0 * float4(1.0f, 0.2f, 0.1f, 0.0f); //(2.0f, 0.8f, 0.6f, 0.0f)若要进行向量与矩阵的乘法,则需要使用mul函数。 2.2.4 数组 float M[4][4]; int p[4]; float3 v[12]; // 12个3D向量除以上类型外,Compute Shader还支持StructuredBuffer和Texture,这两种类型也是我们实际开发中最常使用的。 2.2.5 StructuredBuffer我们可以自定义结构体。结构体可以存放任意数目的标量,向量和矩阵类型,除此之外,它还可以存放数组或者别的结构体类型。 struct A { float4 vec; }; struct B { int scalar; float4 vec; float4x4 mat; float arr[8]; A a; }; // 结构体的访问 B b; b.vec = float4(1.0f, 2.0f, 3.0f, 4.0f);在Compute Shader这边我们一般用StructuredBuffer和RWStructuredBuffer来存储结构体数组,StructuredBuffer对Compute Shader而言是只读的(只能通过C#设置值),RWStructuredBuffer可读®可写(W)。 它们两者在C#这边对应的类是ComputeBuffer。 StructuredBuffer、RWStructuredBuffer和ComputeBuffer如何使用见下面这个例子。 Compute Shader: struct Vertex { float3 pos; float2 uv; } RWStructuredBuffer buffer;C#: // 定义与Compute Shader中结构体相同的结构体 struct Vertex { public Vector3 pos; // c#中的Vector3对应Compute Shader中的float3可对应 public Vector2 uv; // c#中的Vector2可对应float2 } private void RunShader() { // 定义结构体数组 Vertex[] vertex = new Vertex[64]; Vertex[] result = new Vertex[64]; // 初始化vertex数据... // 示例化一个ComuteBuffer,用于和Compute Shader的RWStructuredBuffer交互 // ComputeBuffer构造函数需指定“数组的长度”, “一个结构体所占用的字节数” // 我们的结构体中一共5个float,一个float占4个字节,所以该结构体占20个字节 ComputeBuffer buffer = new ComputeBuffer(vertex.Length, 20); // vertex的设置给ComputeBuffer buffer.SetData(vertex); // 加载ComputeShader ComputeShader cs = Resources.Load("xxx"); // FindKernel("内核"),获取到内核Id int kernel = cs.FindKernel("CSMain"); // 将buffer中的值赋值给Compute Shader中的buffer,将两者联系起来 cs.SetBuffer(kernel, "buffer", buffer); // 执行kernal这个内核 cs.Dispatch(kernel, 8, 8, 1); // 从Compute Shader中读取计算后的值,结果存在result中 buffer.GetData(result); // 不再使用时释放内存 buffer.Dispose(); }从例子可以看出,c#中的Compute Buffer与Compute Shader中StructuredBuffer\RWStructuredBuffer的交互主要就以下几个方法。 1.Compute Buffer实例化,需指定数组的长度,和数组中单个元素占用的字节数 ComputeBuffer buffer = new ComputeBuffer(vertex.Length, 20);2.使用ComputeBuffer.SetData,传入一个数组,将该数组中的值拷贝到ComputeBuffer 需要注意的是数组的长度和单个元素占的字节数要和buffer初始化是指定的值相同。 // vertex的设置给ComputeBuffer buffer.SetData(vertex);3.使用ComputeShader.SetBuffer将buffer指定给Compute Shader中StructuredBuffer\RWStructuredBuffer,参数分别是内核名、Compute Shader中StructuredBuffer\RWStructuredBuffer的变量名、要传递的ComputeBuffer // 将buffer中的值赋值给Compute Shader中的buffer,将两者联系起来 cs.SetBuffer(kernel, "buffer", buffer);4.ComputeShader.Dispatch执行ComputeShader Dispatch中的参数是什么意思?后面我们会讲。 5.最后从Compute Shader中读取计算后的结果,方法为ComputeBuffer.GetData // 从Compute Shader中读取计算后的值,结果存在result中 buffer.GetData(result); 2.2.6 Texture Texture2D xx; // 只读 RWTexture2D xx; // 读写 RWTexture2D xx; // RG_intTexture2d< float4 >对应c#中的Texture2D。 RWTexture2d< float4 >对应c#中的RenderTexture。 在Unity里读写的只能是RenderTexture并且支持随机读写(RenderTexture.enableRandomWrite = true) 与StructuredBuffer类似,c#中使用ComputeShader.SetTexture(内核Id, “ComputeShader中的Texture或RWTexture2D变量名”, c#中的Texture2D或RenderTexture) cs.SetTexture(kernal, "inputTex", inputTexture); 2.3 numthreads与DispatchCompute Shader利用了GPU的并行处理,这里的并行处理是指Compute Shader中的内核方法会被GPU中的多个线程同时运行。 这里的多个线程到底是多少个,是由我们自己确定的。这些线程需要被拆分为多个线程组,一个线程组中包含一定数量的线程,具体方式是通过numthreads和Dispatch来设置。 比如我们可以通过设置numthreads和Dispatch来让一个线程单独处理图像上的一个像素点。 但要注意这种处理是无序的随机的,并不一定是固定的处理顺序,例如不一定是从左到右挨个处理像素点。 2.3.1 numthreads我们看到在内核方法的上方,加上了一个[numthreads(8,8,1)]前缀。 [numthreads(8,8,1)] void CSMain (uint3 id : SV_DispatchThreadID) { // ... }numthreads它的作用是什么呢?它是用来指定线程组(Threads Group)中线程的数量。 什么是线程组呢?可以简单将其理解为是一堆线程的组合。一个线程组,包含有很多线程。 那这么多线程,在线程组中是怎么排列的?类似长方体的排列。 numthreads后面指定了x,y,z三个方向各有多少个线程。画了个图,相信大家一看就明白了。 比如我们指定[numthreads(8,4,2)],其指定了x、y、z轴各8个、4个、2个线程,所以一个线程组共842=64个线程。其线程排列如下,其中一个小立方体代表一个线程(小立方体内的编号我们暂时用不上,但是后面谈到SV_DispatchThreadID的时候我们会用到)。 问题来了,我们把多个线程合成一个线程组的意义在哪儿,有什么好处? 答案是在同一个组的线程咱们可以共享变量,并能够将它们设置为同步。 2.3.3 numthreads中的xyz值何时最优 GPU一次Dispatch会调用64(AMD成为wavefront)或32(NVIDIA称为warp)个线程(这实际上是一种SIMD技术),所以,numThreads的乘积最好是这个值的整数倍。但是Mali不需要这种优化。此外,Metal可以通过API获取这个值。numthreads的数值除了应该为32或64的整数倍外,也是有大小限制的,具体如下表所示。 Compute ShaderMaximum ZMaximum Threads (XYZ)cs_4_x1768cs_5_0641024可以鼠标右键选中一个Compute Shader,然后点击Show compiled code,打开的汇编语言里面有说明是哪个版本,是cs_4_x还是cs_5_0。 ComputeShader.Dispatch用来指定有多少个线程组。 Dispatch用法如下,第一个参数为内核索引值,后面三个参数分别为x、y、z轴的线程组数量。 cs.Dispatch(kernal, 1024/8, 768/8, 1);比如我们设定cs.Dispatch(kernal, 4, 4, 2),则线程组的排列规则如下。 两者的关系弄清楚后,问题又来了,Dispatch中的xyz值怎么设置才是最优的? 这里有一个原则: A Thread Group 运行在一个GPU单元 (A single multiprocesser),如果GPU有16个 multiprocesser,那么程序至少要分成16个 Thread Group使得每个multiprocesser都参与计算。 组之间不分享内存。当然这个原则不是必须的,只是遵循这样的原则效率最高。 一个常用的经验是Dispatch(kernal, 图片长(像素)/numthreads中的x值,图片宽(像素)/numthreads中的y值, 1),即将图像的尺寸除以numthreads的xy。 同时需要注意的是,这样做要满足上面的原则的话,图片的长宽像素最好均为32的整数倍。 比如我们要处理的图像像素为1024×768,numthreads[8, 8, 1],那么按照经验应该设置Dispatch(kernal, 1024/8, 768/8, 1)。 2.4 SV_DispatchThreadID [numthreads(8,8,1)] void CSMain (uint3 id : SV_DispatchThreadID) { // ... }SV_DispatchThreadID用标识当前线程在整个线程组中的位置,是一个三维向量。 由于我们通常通过Dispatch和numthreads来让一个线程处理一个像素点,所以可以通过SV_DispatchThread来获取到当前处理的像素点。 当然除了SV_DispatchThreadID外,我们还可以使用SV_GroupID、SV_GroupThreadID、SV_GroupIndex。 说到这里,Compute Shder的语法就讲得差不多了,最后,咱们去Unity官网看看ComputeShader类的完整API。 Compute Shader: #pragma kernel CSMain Texture2D inputTex; RWTexture2D outputTex; [numthreads(8,8,1)] void CSMain (uint3 id : SV_DispatchThreadID) { float r = inputTex[id.xy].r; float g = inputTex[id.xy].g; float b = inputTex[id.xy].b; float a = inputTex[id.xy].a; float gray = dot(inputTex[id.xy].rgb, float3(0.299, 0.587, 0.114)); outputTex[id.xy] = float4(gray, gray, gray, a); }C#: using UnityEngine; using UnityEngine.UI; public class GrayDemo : MonoBehaviour { private ComputeShader m_GrayComputeShader; private RawImage m_GrayImg; private void Start() { m_GrayImg = GameObject.Find("Canvas/RawImg-ComputeShader").GetComponent(); Texture2D inputTexture = Resources.Load("flower_art_0EN071"); RenderTexture rt = new RenderTexture(inputTexture.width, inputTexture.height, 24); rt.enableRandomWrite = true; rt.Create(); m_GrayImg.texture = rt; m_GrayImg.rectTransform.SetSizeWithCurrentAnchors(RectTransform.Axis.Horizontal, rt.width); m_GrayImg.rectTransform.SetSizeWithCurrentAnchors(RectTransform.Axis.Vertical, rt.height); m_GrayComputeShader = Resources.Load("ComputeShader/Gray"); int kernal = m_GrayComputeShader.FindKernel("CSMain"); m_GrayComputeShader.SetTexture(kernal, "inputTex", inputTexture); m_GrayComputeShader.SetTexture(kernal, "outputTex", rt); m_GrayComputeShader.Dispatch(kernal, 1024/8, 768/8, 1); } }效果如下。 |
 语言 Unity中Compute Shader是用什么语言写的呢?标准的DX11 HLSL。
语言 Unity中Compute Shader是用什么语言写的呢?标准的DX11 HLSL。 然后将下面灰度化纹理的Compute Shader拷贝过去,咱们来看看它的语法。
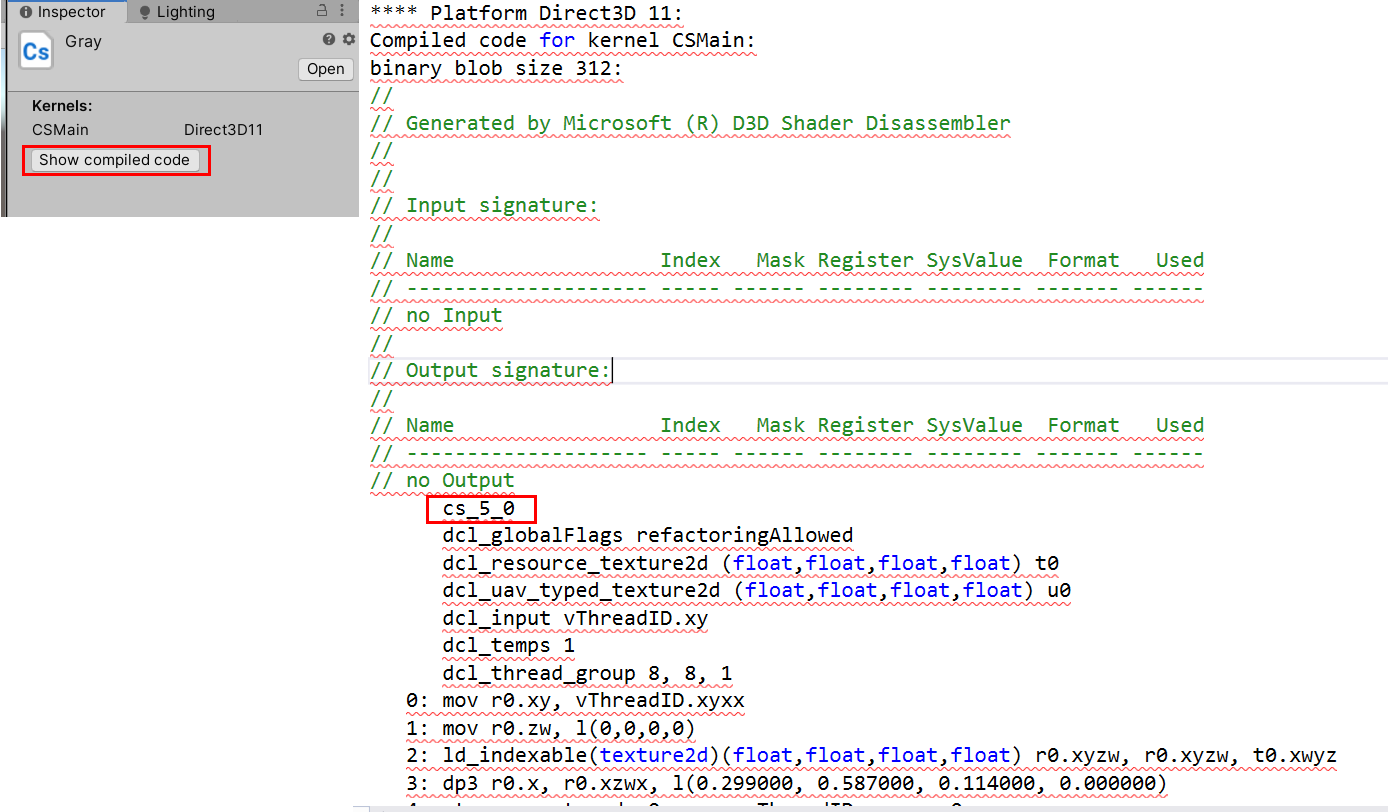
然后将下面灰度化纹理的Compute Shader拷贝过去,咱们来看看它的语法。 又比如[numthreads(8,8,1)],其指定x、y、z轴各8个、8个、2个线程,所以一个线程组共881=64个线程。排列规则如下。
又比如[numthreads(8,8,1)],其指定x、y、z轴各8个、8个、2个线程,所以一个线程组共881=64个线程。排列规则如下。 
 鉴于以上两个条件,我一般在工作中最常使用numthreads(8, 8, 1)。
鉴于以上两个条件,我一般在工作中最常使用numthreads(8, 8, 1)。 如果同时numthreads(8, 8, 1),则numthreads和Dispatch的关系如下。
如果同时numthreads(8, 8, 1),则numthreads和Dispatch的关系如下。 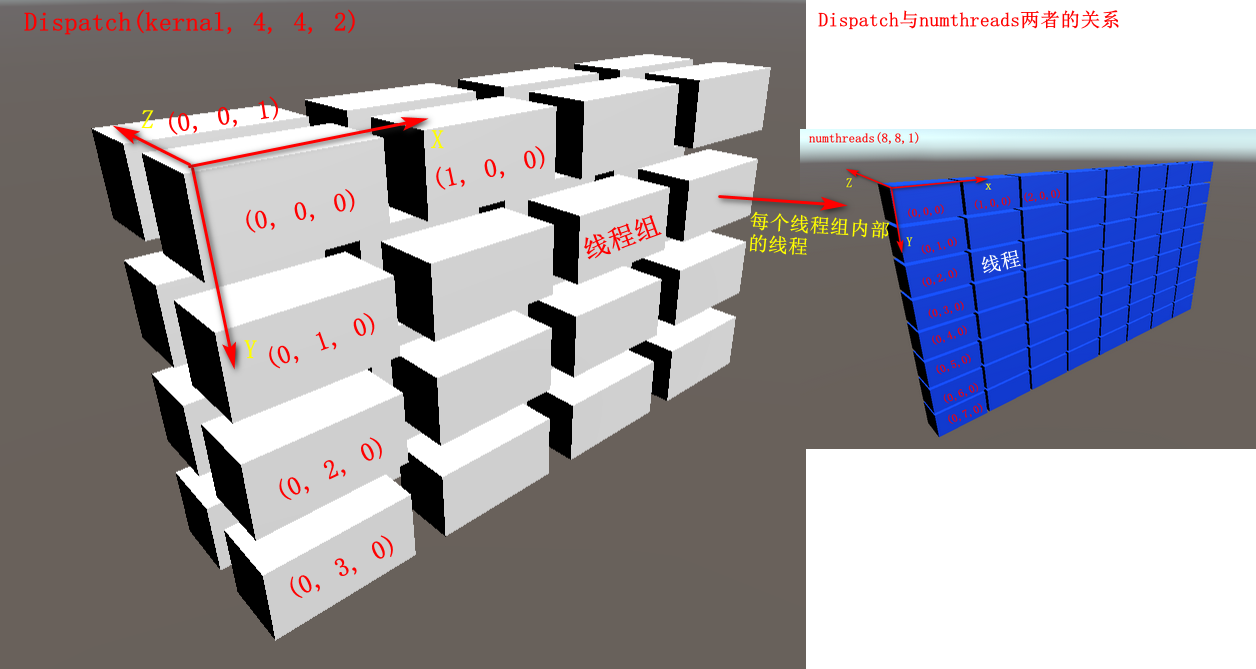 两者的关系,咱们还可以结合nvida和微软的两张图来理解。
两者的关系,咱们还可以结合nvida和微软的两张图来理解。  图片来源:https://www.nvidia.com/content/GTC-2010/pdfs/2260_GTC2010.pdf
图片来源:https://www.nvidia.com/content/GTC-2010/pdfs/2260_GTC2010.pdf 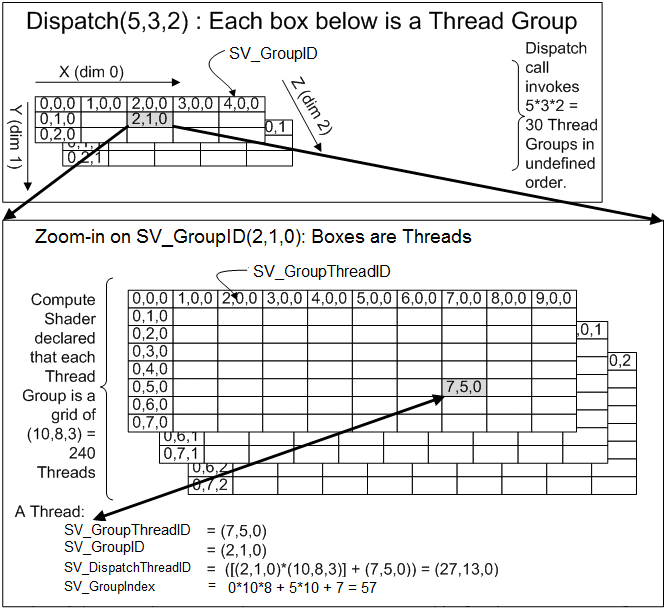 图片来源:https://docs.microsoft.com/en-us/windows/win32/direct3dhlsl/sm5-attributes-numthreads
图片来源:https://docs.microsoft.com/en-us/windows/win32/direct3dhlsl/sm5-attributes-numthreads
 项目链接。 链接:https://pan.baidu.com/s/1V6gqXlKN_YREpiaFXd_Wfg 提取码:z77y 博主个人博客本文链接。
项目链接。 链接:https://pan.baidu.com/s/1V6gqXlKN_YREpiaFXd_Wfg 提取码:z77y 博主个人博客本文链接。【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |