| 【RNN】深入浅出讲解循环神经网络(介绍、原理) | 您所在的位置:网站首页 › RNN网络怎么读 › 【RNN】深入浅出讲解循环神经网络(介绍、原理) |
【RNN】深入浅出讲解循环神经网络(介绍、原理)
|
前馈神经网络不考虑数据之间的关联性,网络的输出只和当前时刻网络的输入相关。然而在解决很多实际问题的时候我们发现,现实问题中存在着很多序列型的数据(文本、语音以及视频等),现实场景如室外的温度是随着气候的变化而周期性的变化的,以及我们的语言也需要通过上下文的关系来确认所表达的含义。 这些序列型的数据往往都是具有时序上的关联性的,既某一时刻网络的输出除了与当前时刻的输入相关之外,还与之前某一时刻或某几个时刻的输出相关。而前馈神经网络并不能处理好这种关联性,因为它没有记忆能力,所以前面时刻的输出不能传递到后面的时刻。 因此,就有了现在的循环神经网络,其本质是:拥有记忆的能力,并且会根据这些记忆的内容来进行推断。因此,它的输出就依赖于当前的输入和记忆。相比于前馈神经网络,该网络内部具有很强的记忆性,它可以利用内部的记忆来处理任意时序的输入序列。 2、RNN的原理循环神经网络(recurrent neural network,简称RNN)源自于1982年由Saratha Sathasivam 提出的霍普菲尔德网络。循环神经网络,是指在全连接神经网络的基础上增加了前后时序上的关系,可以更好地处理比如机器翻译等的与时序相关的问题。 循环神经网络是一种对序列数据有较强的处理能力的网络。在网络模型中不同部分进行权值共享使得模型可以扩展到不同样式的样本,比如CNN网络中一个确定好的卷积核模板,几乎可以处理任何大小的图片。将图片中分成多个区域,使用同样的卷积核对每一个区域进行处理,最后可以获得非常好的处理结果。同样的,循环网络使用类似的模块(形式上相似)对整个序列进行处理,可以将很长的序列进行泛化,得到需要的结果。 RNN的目的就是用来处理序列数据的。在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题都无能无力。比如你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的。
相比于词袋模型和前馈神经网络模型,RNN可以考虑到词的先后顺序对预测的影响,RNN包括三个部分:输入层、隐藏层和输出层。相对于前馈神经网络,RNN可以接收上一个时间点的隐藏状态。 3、RNN的网络结构RNN 不是刚性地记忆所有固定长度的序列,而是通过隐藏状态来存储之前时间步的信息。
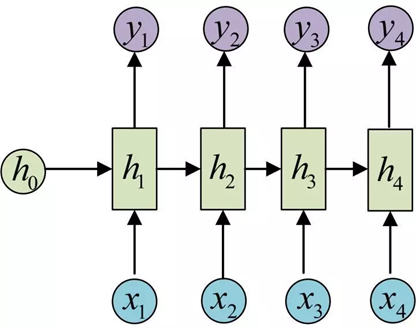
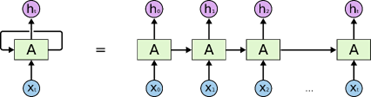
图1 典型的 RNN 是有环结构 由上图可见:一个典型的 RNN 网络架构包含一个输入,一个输出和一个神经网络单元 。和普通的前馈神经网络的区别在于:RNN 的神经网络单元不但与输入和输出存在联系,而且自身也存在一个循环 / 回路 / 环路 / 回环 (loop)。这种回路允许信息从网络中的一步传递到下一步。 同时,RNN 还能按时间序列展开循环 (unroll the loop) 为如下形式:
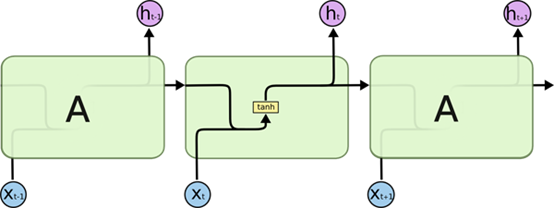
图2 展开的 RNN 以上架构不仅揭示了 RNN 的实质:上一个时刻的网络状态将会作用于(影响)到下一个时刻的网络状态,还表明 RNN 和序列数据密切相关。同时,RNN 要求每一个时刻都有一个输入,但是不一定每个时刻都需要有输出。 进一步地,公式化 RNN 的结构:
图3 单个展开的RNN结构
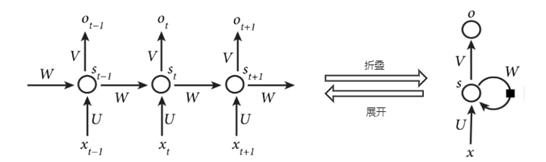
图4 RNN的计算结构图 其中,圆形的箭头表示隐藏层的自连接。在RNN中,每一层都共享参数U、V、W,降低了网络中需要学习的参数,提高学习效率。 输入单元(input units): 隐藏单元(hidden units): 输出单元(output units): 输入层: 隐藏层: 输出层: 循环神经网络的输入是序列数据,每个训练样本是一个时间序列,包含多个相同维度的向量。网络的参数如何通过训练确定?这里就要使用解决循环神经网络训练问题的 Back Propagation Through Time 算法,简称BPTT。 循环神经网络的每个训练样本是一个时间序列,同一个训练样本前后时刻的输入值之间有关联,每个样本的序列长度可能不相同。训练时先对这个序列中的每个时刻的输入值进行正向传播,再通过反向传播计算出参数的梯度值并更新参数。 循环神经网络在进行反向传播时也面临梯度消失或者梯度爆炸问题,这种问题表现在时间轴上。如果输入序列的长度很长,人们很难进行有效的参数更新。通常来说梯度爆炸更容易处理一些。梯度爆炸时我们可以设置一个梯度阈值,当梯度超过这个阈值的时候可以直接截取。 有三种方法应对梯度消失问题: (1)合理的初始化权重值。初始化权重,使每个神经元尽可能不要取极大或极小值,以躲开梯度消失的区域。 (2) 使用 ReLu 代替 sigmoid 和 tanh 作为激活函数。 (3) 使用其他结构的RNNs,比如长短时记忆网络(LSTM)和 门控循环单元 (GRU),这是最流行的做法。 4、PyTorch的使用pytorch 中使用 nn.RNN 类来搭建基于序列的循环神经网络,它的构造函数有以下几个参数: input_size:输入数据X的特征值的数目。 hidden_size:隐藏层的神经元数量,也就是隐藏层的特征数量。 num_layers:循环神经网络的层数,默认值是 1。 bias:默认为 True,如果为 false 则表示神经元不使用 bias 偏移参数。 batch_first:如果设置为 True,则输入数据的维度中第一个维度就是 batch 值,默认为 False。默认情况下第一个维度是序列的长度, 第二个维度才是batch,第三个维度是特征数目。 dropout:如果不为空,则表示最后跟一个 dropout 层抛弃部分数据,抛弃数据的比例由该参数指定。RNN 中最主要的参数是 input_size 和 hidden_size,这两个参数务必要搞清楚。其余的参数通常不用设置,采用默认值就可以了。 rnn = torch.nn.RNN(20,50,2) input = torch.randn(100 , 32 , 20) h_0 =torch.randn(2 , 32 , 50) output,hn=rnn(input ,h_0) print(output.size(),hn.size()) ''' torch.Size([100, 32, 50]) torch.Size([2, 32, 50]) '''关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧! |

【本文地址】