| python | 您所在的位置:网站首页 › Python求质数的和与积 › python |
python
|
目录
目录 目录 1.pandas库简介(https://www.gairuo.com/p/pandas-overview) 1.pandas库简介(https://www.gairuo.com/p/pandas-overview)用途: Pandas 可以用来进来各种表格数据处理,实现复杂的处理逻辑,这些往往是 Excel 等工具无法处理的,还可以自动化、批量化,对于相同的大量的数据处理我们不需要重复去工作。 适用的数据: Pandas 适合处理一个规正的二维数据(如图),即有 N 行 N 列,类似于 SQL 执行后产出的,或者无合并单元格Excel 表格这样的数据。它可以把多个文件的数据合并在一起,如果结构不一样,也可以经过处理进行合并。
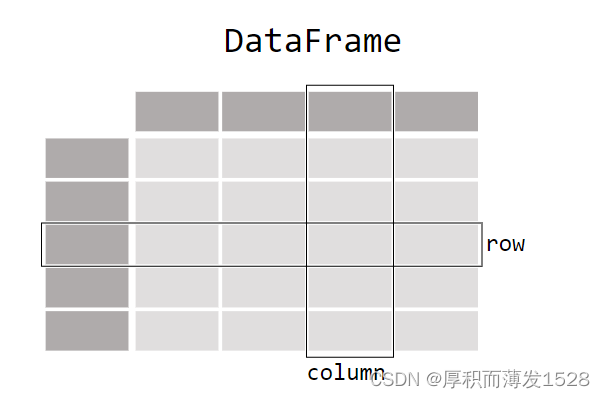
基本功能: 从 Excel、CSV、网页、SQL、剪贴板等读取数据合并多个文件或者 sheet 数据,拆分数据为独立文件数据清洗,如去重、缺失值、填充默认值、格式补全、极端值处理等建立高效的索引支持大体量数据按一定业务逻辑插入计算后的列、删除列灵活方便的数据查询、筛选分组聚合数据,可独立指定分组后的各字段计算方式数据的转置,如行转列列转行变更处理连接数据库,直接 SQL 查询数据并进行处理对时序数据进行分组采样,如按月、按季、按工作小时,也可以自定义周期,如工作日窗口计划,移动窗口统计、日期移动等灵活的可视化图表输出,支持所有的统计图形融合在表格的样式风格,提高数据识别效率 2.pandas库read_csv方法(https://zhuanlan.zhihu.com/p/340441922?utm_medium=social&utm_oi=27819925045248) pandas.read_csv方法函数用来读取CSV格式数据文件,默认返回DataFrame格式的数据DataFrame格式: 是Pandas库中的一种数据结构,类似excel或者sql中的表
1. filepath_or_buffer:数据输入的路径:可以是文件路径、可以是URL,也可以是实现read方法的任意对象。这个参数,就是我们输入的第一个参数 import pandas as pd pd.read_csv("girl.csv")# 还可以是一个URL,如果访问该URL会返回一个文件的话,那么pandas的read_csv函数会自动将 该文件进行读取。比如:我们用fastapi写一个服务,将刚才的文件返回。 pd.read_csv("http://localhost/girl.csv")# 里面还可以是一个 _io.TextIOWrapper,比如: f = open("girl.csv", encoding="utf-8") pd.read_csv(f)
2. 索引列 index_col: 我们在读取文件之后所得到的DataFrame的索引默认是0、1、2……,我们可以通过set_index设定索引,但是也可以在读取的时候就指定某列为索引 pd.read_csv('girl.csv', delim_whitespace=True, index_col="name") # int, str, sequence of int / str, or False, default None # 默认为 `None`, 自动识别索引 pd.read_csv(data, index_col=False) # 不再使用首列作为索引 pd.read_csv(data, index_col=0) # 第几列是索引 pd.read_csv(data, index_col='年份') # 指定列名 pd.read_csv(data, index_col=['a','b']) # 多个索引 pd.read_csv(data, index_col=[0, 3]) # 按列索引指定多个索引
3. dtype:在读取数据的时候,设定字段的类型。比如,公司员工的id一般是:00001234,如果默认读取的时候,会显示为1234,所以这个时候要把他转为字符串类型,才能正常显示为00001234: df = pd.read_csv('girl.csv', delim_whitespace=True) df = pd.read_csv('girl.csv', delim_whitespace=True, dtype={"id": str})
4.usecols:如果一个数据集中有很多列,但是我们在读取的时候只想要使用到的列,我们就可以使用这个参数 pd.read_csv('girl.csv', delim_whitespace=True, usecols=["name", "address"])
5.sep:读取csv文件时指定的分隔符,默认为逗号。注意:"csv文件的分隔符" 和 "我们读取csv文件时指定的分隔符" 一定要一致。 pd.read_csv("girl.csv")
由于指定的分隔符 和 csv文件采用的分隔符 不一致,因此多个列之间没有分开,而是连在一起了。 所以,我们需要将分隔符设置成"\t"才可以。 pd.read_csv('girl.csv', sep='\t')
6. delim_whitespace :默认为 False,设置为 True 时,表示分割符为空白字符,可以是空格、"\t"等等。不管分隔符是什么,只要是空白字符,那么可以通过delim_whitespace=True进行读取。 pd.read_csv('girl.csv',delim_whitespace=True)
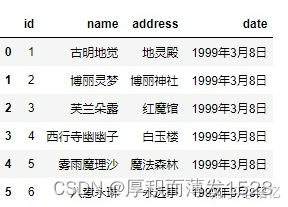
7.names:当names没被赋值时,header会变成0,即选取数据文件的第一行作为列名;当 names 被赋值,header 没被赋值时,那么header会变成None。如果都赋值,就会实现两个参数的组合功能 1) names 没有被赋值,header 也没赋值: # 这种情况下,header为0,即选取文件的第一行作为表头 pd.read_csv('girl.csv',delim_whitespace=True)
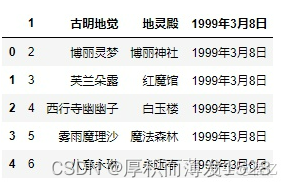
2) names 没有被赋值,header 被赋值: # 不指定names,指定header为1,则选取第二行当做表头,第二行下面为数据 pd.read_csv('girl.csv',delim_whitespace=True, header=1)
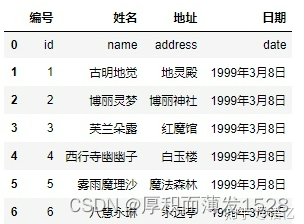
3) names 被赋值,header 没有被赋值: pd.read_csv('girl.csv', delim_whitespace=True, names=["编号", "姓名", "地址", "日期"])
更多参数解析请参考文档(https://zhuanlan.zhihu.com/p/340441922?utm_medium=social&utm_oi=27819925045248) 举例: data.csv格式数据样式:
查看数据: import pandas as pd data = pd.read_csv('./data.csv',index_col='A') print(data) index = data.index col = data.columns print(index) print(col) # 取索引为'a'的行 print(data.loc['a'])打印结果: A B C D E F a 1 2 3 4 5 6 b 7 8 9 10 11 12 c 13 14 15 16 17 18 d 19 20 21 22 23 24 e 25 26 27 28 29 30 f 31 32 33 34 35 36 g 37 38 39 40 41 42 h 43 44 45 46 47 48 Index(['A, '1', '7', '13', '19', '25', '31', '37', '43'], dtype='object') Index(['A', 'B', 'C', 'D', 'E', 'F'], dtype='object') A 1 B 2 C 3 D 4 E 5 F 6
|









【本文地址】