| Tensorflow 2.0 中模型构建的三种方式(三种模型的定义方式) | 您所在的位置:网站首页 › Python创建类有几种方法 › Tensorflow 2.0 中模型构建的三种方式(三种模型的定义方式) |
Tensorflow 2.0 中模型构建的三种方式(三种模型的定义方式)
|
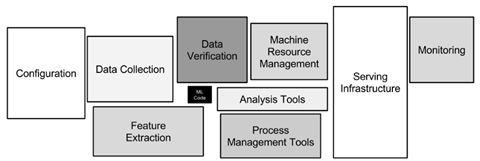
文章目录: 目录 1. 三种定义模型的方式2. 三种方式使用的优先级3. 三种模型的定义方式3.1 Sequential API3.2 Functional API3.3 Subclassing API 4. 训练模式(training mode)和推理模式(inference mode)下模型的使用4.1 Keras Sequential 方式构建的模型4.2 Keras Functional API方式构建的模型4.3 Keras Model Subclassing 方式构建的模型 5. 总结5.1 符号APIs的好处和局限性5.1.1好处5.1.2 局限性 5.2命令式APIs的好处和局限性5.2.1 好处5.2.2 局限性 6. 参考文章 1. 三种定义模型的方式keras和tensorflow2.0提供了三种定义模型的方式: a. Sequential API b. Functional API c. Subclassing API 这就需要我们了解如何使用这三种方法来定义模型,还要学会什么时候该用什么方法 2. 三种方式使用的优先级先考虑能不能用Keras Sequential APIs 方式建立需要的模型,如果不能,在考虑能不能使用Keras Functional APIs方式来建立你需要的模型,如果还是不能,最后再考虑Keras Model Subclassing APIs方式 3. 三种模型的定义方式 3.1 Sequential API当我们想到神经网络时,我们通常使用的模型是一个“层图”,如下图: 使用和实例化 model = shallownet_sequential(width,height,depth,classes) outputs = model(inputs) 3.2 Functional APITensorFlow 2.0提供了另一个符号模型构建api:Keras Functional。序列化用于堆叠,你可能已经猜到了,函数用于DAGs。 • ResNet • GoogleNet/Inception • Xception • SqueezeNet 下面定义一个mini的GoogleNet,原文参见文档 1.comv_module:卷积模块,进行卷积,batchnorm,relu的操作,定义模块,方便复用。 2.inception_module:包括两个卷积模块,卷积核以(3,3)和(1,1)实现,padding=same,两个通道的输出会被拼接起来。 3.downsample_module:作用是减小尺寸。有两个分支:一个是卷积下采样,33的卷积核,stride=22,padding=‘valid’。另一个下采样方法是最大值池化,pool_size=33,strides=22,padding=valid,最后的输出拼接起来。 实现以上三种模块,然后通过各种组合,组成模型 def conv_module(x,k,kx,ky,stride,chandim,padding="same"): #conv-bn-relu x = Conv2D(k,(kx,ky),strides=stride,padding=padding)(x) x = BatchNormalization(axis=chandim)(x) x = Activation('relu')(x) return x def inception_module(x,num1x1,num3x3,chandim): conv_1x1 = conv_module(x,num1x1,1,1,(1,1),chandim) conv_3_3 = conv_module(x,num3x3,3,3,(1,1),chandim) x = concatenate([conv_1x1,conv_3_3],axis=chandim) return x def downsample_module(x,k,chandim): #conv downsample and pool downsample conv_3x3 = conv_module(x,k,3,3,(2,2),chandim,padding='valid') pool = MaxPooling2D((3,3),strides=(2,2))(x) x = concatenate([conv_3x3,pool],axis=chandim) return x #然后定义整个MiniGoogLeNet def minigooglenet_functional(width,height,depth,classes): inputshape=(height,width,depth) chandim=-1 #define inputs and firse conv inputs = Input(shape=inputshape) x = conv_module(inputs,96,3,3,(1,1),chandim) #def two inception and followed by a downsample x = inception_module(x,32,32,chandim) x = inception_module(x,32,48,chandim) x = downsample_module(x,80,chandim) #def four inception and one downsample x = inception_module(x,112,48,chandim) x = inception_module(x,96,64,chandim) x = inception_module(x,80,80,chandim) x = inception_module(x,48,96,chandim) x = downsample_module(x,96,chandim) #def two inception followed by global pool and dropout x = inception_module(x,176,160,chandim) x = inception_module(x,176,160,chandim) x = AveragePooling2D((7,7))(x) x = Dropout(0.5)(x) #softmax x = Flatten()(x) x = Dense(classes)(x) x = Activation('softmax')(x) #create the model model = Model(inputs,x,name='MiniGoogLeNet') return model实例化和使用 model = minigooglenet_functional(32,32,3,10) y = model(x) 3.3 Subclassing API在命令式中,可以像NumPy那样编写模型,用这种风格构建模型感觉像面向对象编程。下面是一个子类模型的快速例子: Keras 模型类定义示意图 这里,我们没有显式地声明 a 和 b 两个变量并写出 y_pred = a * X + b 这一线性变换,而是建立了一个继承了 tf.keras.Model 的模型类 Linear 。这个类在初始化部分实例化了一个 全连接层 (tf.keras.layers.Dense ),并在 call 方法中对这个层进行调用,实现了线性变换的计算。 Keras 的全连接层:线性变换 + 激活函数 全连接层 (Fully-connected Layer,tf.keras.layers.Dense ) 是 Keras 中最基础和常用的层之一,对输入矩阵 进行 的线性变换 + 激活函数操作。如果不指定激活函数,即是纯粹的线性变换 。具体而言,给定输入张量 input = [batch_size, input_dim] ,该层对输入张量首先进行 tf.matmul(input, kernel) + bias 的线性变换 ( kernel和 bias 是层中可训练的变量),然后对线性变换后张量的每个元素通过激活函数 activation ,从而输出形状为 [batch_size, units] 的二维张量。 这种方式构建的实例model,在training mode下,可以直接使用model(inputs,training=True);在inference mode 下,可以直接使用model(inputs,training=False), 我们知道,在Python中对类的实例 class_object进行形如class_object()的调用,等价于class_object.call()。而在Tensorflow中,call()方法中又调用了call()方法,这个方法才是我们关注点所在 我们可以通过help函数来查看一下该call()方法的用法(可以看到training参数): >>> help(tf.keras.Sequential.call) Help on function call in module tensorflow.python.keras.engine.sequential: call(self, inputs, training=None, mask=None) Calls the model on new inputs. In this case `call` just reapplies all ops in the graph to the new inputs (e.g. build a new computational graph from the provided inputs). Arguments: inputs: A tensor or list of tensors. training: Boolean or boolean scalar tensor, indicating whether to run the `Network` in training mode or inference mode. mask: A mask or list of masks. A mask can be either a tensor or None (no mask). Returns: A tensor if there is a single output, or a list of tensors if there are more than one outputs. 4.2 Keras Functional API方式构建的模型这种方式构建的实例model,在training mode下,也是直接使用model(inputs,training=True);在inference mode 下,也是直接使用model(inputs,training=False). 我们可以通过help函数来查看一下该call()方法的用法(可以看到training参数): >>> help(tf.keras.Model.call) Help on function call in module tensorflow.python.keras.engine.network: call(self, inputs, training=None, mask=None) Calls the model on new inputs. In this case `call` just reapplies all ops in the graph to the new inputs (e.g. build a new computational graph from the provided inputs). Arguments: inputs: A tensor or list of tensors. training: Boolean or boolean scalar tensor, indicating whether to run the `Network` in training mode or inference mode. mask: A mask or list of masks. A mask can be either a tensor or None (no mask). Returns: A tensor if there is a single output, or a list of tensors if there are more than one outputs. 4.3 Keras Model Subclassing 方式构建的模型使用这种方式构建模型,有个特点,就是在模型类中必须手工重载实现其call()方法,换句话来说,就是call()方法的参数training必须由自己来管理,如下例子: class self_model(tf.keras.Model): def __init__(self): super().__init__() self.flatten = tf.keras.layers.Flatten() self.dense1 = tf.keras.layers.Dense(units=100) self.bn = tf.keras.layers.BatchNormalization() self.dense2 = tf.keras.layers.Dense(units=10) def call(self, inputs, training=None): x = self.flatten(inputs) x = tf.nn.relu(self.bn(self.dense1(x), training=training)) output = tf.nn.softmax(self.dense2(x)) return output在上面这个例子中,BatchNormalization层的实例self.bn在调用过程中给,需要我们手工传入training参数,使得它在训练模式和推理模式表现出不同的行为。 而在前面两种构建模型的方式中,我们不需要手工管理training参数,只需要在使用模型类实例model时,隐式调用其call()方法,传入正确的training参数值即可。Tensorflow在底层构建模型是就会根据我们传入的training参数值,自动给BatchNormalization层和dropout层赋予不同的行为。 前面两种构建模型的方式中,我们不需要在模型内部调用BatchNormalization层时传入training参数值,只需要在模型实例化时,传入,而第三种方式需要。 5. 总结a. sequential的方式用来实现一层接着一层的模型 b. functional的模型能完成大多数模型 c. subclassing的模型能完全自定义,但是比较复杂 所常归来说,用functional就好了。 5.1 符号APIs的好处和局限性 5.1.1好处使用符号APIs,模型是类似于图的数据结构,这意味着可以检查或者总结模型(你可以将它挥着为一个图像来显示图(使用keras.utils.plot_model)或者简单的使用model.summary(),或者查看图层、权重和形状描述。) 同样,当将层连接在一起时,库设计人员可以运行兼容性检查(在构建模型时和执行之前) • 这类似于编译器中的类型检查,可以极大地减少开发人员的错误。 • 大多数调试将在模型定义阶段进行,而不是在执行阶段。你可以保证任何编译的模型都会运行。这使得迭代更快,调试更容易 符号模型提供一致的API。这使得它们易于重用和共享。例如,在迁移学习中,你可以访问中间层激活来从现有的模型构建新的模型,如下所示: from tensorflow.keras.applications.vgg19 import VGG19 base = VGG19(weights=’imagenet’) model = Model(inputs=base.input,outputs=base_model.get_layer(‘block4_pool’).output) image = load(‘elephant.png’) block4_pool_features = model.predict(image)符号模型是由数据结构定义的,这使得它们可以自然地复制或克隆。 例如,序列化api和函数api为你提供了model.get_config()、 model.to_json() 、model.save()、clone_model(model)等功能,可以从数据结构中重新创建相同的模型(无需访问用于定义和训练模型的原始代码)。 虽然一个设计良好的API应该匹配我们的神经网络模型,但同样重要的是匹配我们作为程序员的心智模型。对于我们许多人来说,这是一种命令式的编程风格。在符号API中,你在操作“符号张量”(这些张量尚未包含任何值)来构建图形。Keras序列化API和函数API“感觉到”命令。它们的设计使得许多开发人员没有意识到他们一直在使用符号来定义模型。 5.1.2 局限性当前生成的符号api是最适合开发的有向无环图模型。这在实践中占了大多数用例,尽管有一些特殊的用例不适合这种简洁的抽象,例如,动态网络(如树状rnns)和递归网络。 这就是为什么TensorFlow还提供了一种命令式的模型构建API风格(Keras子类化,如上所示)。你可以使用序列化api和函数api中所有熟悉的层、初始化器和优化器。这两种样式也是完全可互操作的,因此你可以混合和匹配(例如,你可以将一种模型类型嵌套到另一种模型类型中)。你可以将符号模型用作子类模型中的一个层,或者反过来。 5.2命令式APIs的好处和局限性 5.2.1 好处你的前向传递是强制编写的,这使得用你自己的实现替换库实现的部件(例如,层、激活或丢失函数)变得很容易。这对于编程来说是很自然的,也是深入学习深层知识的好方法。 这使得快速尝试新想法变得容易(DL开发工作流变得与面向对象的Python相同),并且对研究人员特别有帮助。 使用Python,在模型的正向传递中指定任意控制流也很容易。 命令式api为你提供了最大的灵活性,但这是有代价的。我也喜欢用这种风格编写代码,但是我想花点时间来强调一下它的局限性(注意权衡利弊是有好处的)。 5.2.2 局限性重要的是,在使用命令式API时,模型是由类方法的主体定义的。你的模型不再是透明的数据结构,而是一段不透明的字节码。当使用这种风格时,你是在用可用性和重用性来换取灵活性。 调试发生在执行过程中,而不是在定义模型时。 几乎没有对输入或层间兼容性的检查,所以当使用这种风格时,很多调试负担从框架转移到开发人员身上。 命令式模型可能更难于重用。例如,你不能使用一致的API访问中间层或激活。 相反,提取激活的方法是用新的调用(或前向)方法编写一个新类。最初写可能很有趣,也很简单,但如果没有标准,它可能会为以后埋坑。 命令式模型也更难于检查、复制或克隆。 例如,model.save()、model.get_config()和clone_model不能用于子类化的模型。类似地,model.summary()只给出一个层列表(不提供关于它们如何连接的信息,因为这是不可访问的)。 重要的是要记住,模型构建只是在实践中使用机器学习的一小部分。 模型本身(指定层、训练循环等的代码部分)是位于中间的小框。 在实际的ML系统中,只有一小部分由ML代码组成,如中间的小黑盒子所示 符号定义的模型在可重用性、调试和测试方面具有优势。例如,在教学的时候,如果他们使用序列化API,我可以立即调试学生的代码。当他们使用子类模型时(不管框架是什么),会花费更长的时间(bug可能更微妙,而且有很多类型)。 TensorFlow 2.0支持这两种样式,所以你可以为你的项目选择合适的抽象级别(和复杂性)。 • 如果你的目标是易用性、低概念开销,并且你喜欢将模型看作层图:使用Keras序列化API或函数API(如将LEGO积木连接在一起)和内置的训练循环。这是解决大多数问题的正确方法。 • 如果你想把你的模型看作一个面向对象的Python/Numpy开发人员,并且你优先考虑灵活性和可编程性,Keras子类化是适合你的API。 6. 参考文章https://blog.csdn.net/u011119817/article/details/102922269 https://blog.csdn.net/u011984148/article/details/99440017 https://blog.csdn.net/weixin_42398658/article/details/94558546 https://zhuanlan.zhihu.com/p/99936722 https://blog.csdn.net/zkbaba/article/details/100172705 https://www.jianshu.com/p/f5510ecdcc28 http://www.360doc.com/content/19/0717/23/32196507_849458543.shtml |
 这个图可以是左边显示的有向无环图,也可以是右边显示的堆叠形式,我们使用符号来构建模型时,我们通过描述这个图的结构来实现。 下面是keras序列化API符号化构建模型的快速示例:
这个图可以是左边显示的有向无环图,也可以是右边显示的堆叠形式,我们使用符号来构建模型时,我们通过描述这个图的结构来实现。 下面是keras序列化API符号化构建模型的快速示例:  在上面的示例中,我们定义了一组层,然后使用内置的训练循环model.fit对其进行训练 用keras构建模型就像“把乐高积木塞在一起”一样简单。为什么,除了匹配我们认知的模型外,以这种方式构建的模型很容易调试
在上面的示例中,我们定义了一组层,然后使用内置的训练循环model.fit对其进行训练 用keras构建模型就像“把乐高积木塞在一起”一样简单。为什么,除了匹配我们认知的模型外,以这种方式构建的模型很容易调试  图中显示了上面代码创建的模型(使用plot_model构建)。 序列模型是layer-by-layer的,它是最简单的定义模型的方法,但是有几个不足: • 不能够共享某一层 • 不能有多个分支 • 不能有多个输入 这种结构的经典网络比如有:Lenet5,AlexNet,VGGNet 定义一个简单的Sequential模型
图中显示了上面代码创建的模型(使用plot_model构建)。 序列模型是layer-by-layer的,它是最简单的定义模型的方法,但是有几个不足: • 不能够共享某一层 • 不能有多个分支 • 不能有多个输入 这种结构的经典网络比如有:Lenet5,AlexNet,VGGNet 定义一个简单的Sequential模型 一个快速的示例,使用函数API创建一个多输入/多输出模型 函数API是一种创建更灵活模型的方法。它可以处理非线性拓扑、具有共享层的模型和具有多个输入或输出的模型。 函数式API有更强的功能 • 定义更复杂的模型 • 支持多输入多输出 • 可以定义模型分支,比如inception block , resnet block • 方便layer共享 另外,对于任意的Sequential模型,都可以用函数式编程方式来实现。 函数式模型示例有:
一个快速的示例,使用函数API创建一个多输入/多输出模型 函数API是一种创建更灵活模型的方法。它可以处理非线性拓扑、具有共享层的模型和具有多个输入或输出的模型。 函数式API有更强的功能 • 定义更复杂的模型 • 支持多输入多输出 • 可以定义模型分支,比如inception block , resnet block • 方便layer共享 另外,对于任意的Sequential模型,都可以用函数式编程方式来实现。 函数式模型示例有: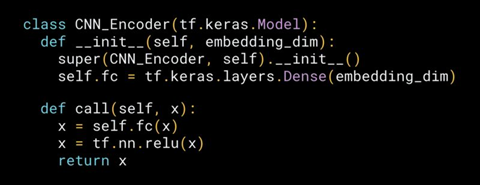 从开发人员的角度来看,这种工作方式是扩展框架定义的模型类,实例化层,然后编写模型的正向传递(自动生成向后传递) TensorFlow 2.0通过Keras Subclassing API支持这种开箱即用的方式。在keras中Model类做为基本的类,可以在些基础上,进行会任意个人设置,带来很强的自由。但同进带来的不足就是没用序列和函数定义模型使用起来简单。既然子类方法有些难,为什么还要用呢,因为这对一些研究人员很好,可以模型所以部分进行控制。
从开发人员的角度来看,这种工作方式是扩展框架定义的模型类,实例化层,然后编写模型的正向传递(自动生成向后传递) TensorFlow 2.0通过Keras Subclassing API支持这种开箱即用的方式。在keras中Model类做为基本的类,可以在些基础上,进行会任意个人设置,带来很强的自由。但同进带来的不足就是没用序列和函数定义模型使用起来简单。既然子类方法有些难,为什么还要用呢,因为这对一些研究人员很好,可以模型所以部分进行控制。 继承 tf.keras.Model 后,我们同时可以使用父类的若干方法和属性,例如在实例化类 model = Model() 后,可以通过 model.variables 这一属性直接获得模型中的所有变量,免去我们一个个显式指定变量的麻烦。 简单的线性模型 y_pred = a * X + b ,我们可以通过模型类的方式编写如下:
继承 tf.keras.Model 后,我们同时可以使用父类的若干方法和属性,例如在实例化类 model = Model() 后,可以通过 model.variables 这一属性直接获得模型中的所有变量,免去我们一个个显式指定变量的麻烦。 简单的线性模型 y_pred = a * X + b ,我们可以通过模型类的方式编写如下: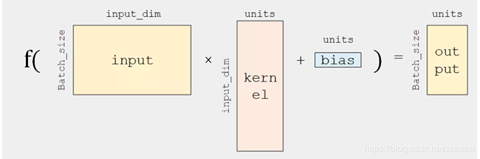

【本文地址】