| 【项目实战】Python实现LightGBM分类模型(LGBMClassifier算法)项目实战 | 您所在的位置:网站首页 › Python分类模型的构建方法 › 【项目实战】Python实现LightGBM分类模型(LGBMClassifier算法)项目实战 |
【项目实战】Python实现LightGBM分类模型(LGBMClassifier算法)项目实战
|
说明:这是一个机器学习实战项目(附带数据+代码+文档+代码讲解),如需数据+代码+文档+代码讲解可以直接到文章最后获取。
如今已是大数据时代,具备大数据思想至关重要,人工智能技术在各行各业的应用已是随处可见。GBDT (Gradient Boosting Decision Tree) 是机器学习中一个长盛不衰的模型,其主要思想是利用弱分类器(决策树)迭代训练以得到最优模型,该模型具有训练效果好、不易过拟合等优点。GBDT不仅在工业界应用广泛,通常被用于多分类、点击率预测、搜索排序等任务;在各种数据挖掘竞赛中也是致命武器,据统计很多比赛有一半以上的冠军方案都是基于GBDT。而LightGBM(Light Gradient Boosting Machine)是一个实现GBDT算法的框架,支持高效率的并行训练,并且具有更快的训练速度、更低的内存消耗、更好的准确率、支持分布式可以快速处理海量数据等优点。 2.数据获取本次建模数据来源于网络(本项目撰写人整理而成),数据项统计如下:
数据详情如下(部分展示):
真实数据中可能包含了大量的缺失值和噪音数据或人工录入错误导致有异常点存在,非常不利于算法模型的训练。数据清洗的结果是对各种脏数据进行对应方式的处理,得到标准的、干净的、连续的数据,提供给数据统计、数据挖掘等使用。数据预处理通常包含数据清洗、归约、聚合、转换、抽样等方式,数据预处理质量决定了后续数据分析挖掘及建模工作的精度和泛化价值。以下简要介绍数据预处理工作中主要的预处理方法: 3.1 用Pandas工具查看数据 使用Pandas工具的head()方法查看前五行数据:
关键代码:
3.2查看数据集摘要 使用Pandas工具的info()方法查看数据集的摘要信息: 从上图可以看到,总共有569条数据,6个数据项,所有数据中没有缺失值。 关键代码:
4.1检查目标变量的分布 用Pandas工具的value_counts()方法进行统计,输出结果如下: 图形化展示如下:
从上面两个图中可以看到,分类为1的有347条/分类为0的有212条,数据偏差不大。另外,可以看到这是一个二分类的任务。 4.2 相关性分析 用Pandas工具的corr()方法 matplotlib seaborn进行相关性分析,结果如下: 通过上图可以看到,数据项之间正值是正相关/负值是负相关,数值越大 相关性越强。 5.特征工程5.1 建立特征数据和标签数据 diagnosis为标签数据,除 diagnosis之外的为特征数据。关键代码如下: 5.2数据集拆分 训练集拆分,分为训练集和验证集,70%训练集和30%验证集。关键代码如下: 主要使用使用LGBMClassifier算法,用于目标分类。 6.1模型参数
由于上述参数的值是默认值,所有在建模的代码中直接用的默认值。 关键代码如下:
7.1评估指标及结果 评估指标主要包括准确率、查准率、查全率、F1分值等等。
从上表可以看出,准确率为93% F1分值为95%,lightgbm分类模型比较优秀,效果非常好。 关键代码如下:
7.2 查看是否过拟合 查看训练集和测试集的分数: 通过结果可以看到,训练集分数和测试集分数基本相当,所以没有出现过拟合现象。 关键代码:
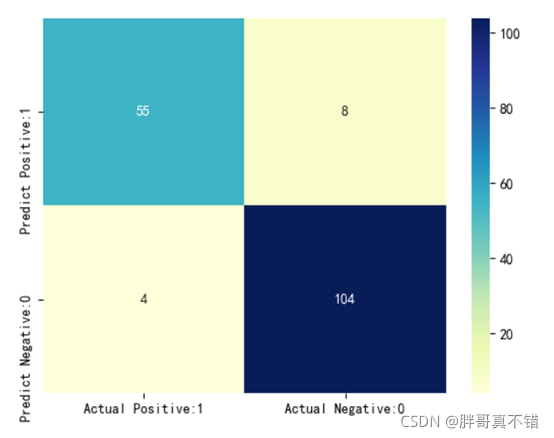
7.3 混淆矩阵 lightgbm分类模型混淆矩阵:
从上图可以看到,实际值为1 预测为0的有4个;实际值为0 预测为1的有8个;这些是预测错误的,总共12个,在可以接受的范围内。 7.4 分类报告 lightgbm分类模型分类报告: 从上图可以看到,分类类型为0的F1分值为0.90;分类类型为1的F1分值为0.95;整个模型的准确率为0.93. 7.5 模型特征重要性 从上图可以看到特征变量对此模型的重要性依次为:mean_smoothness、mean_texture、mean_perimeter、mean_radius、mean_area等等。 7.6 ROC曲线 从上图可以看出AUC值为0.98,模型非常棒。 8.结论与展望综上所述,本文采用了lightgbm分类模型,最终证明了我们提出的模型效果良好。准确率达到了93%,可用于日常生活中进行建模预测,以提高价值。 本次机器学习项目实战所需的资料,项目资源如下: 项目说明: 链接:https://pan.baidu.com/s/1dW3S1a6KGdUHK90W-lmA4w 提取码:bcbp 网盘如果失效,可以添加博主微信:zy10178083 |



















【本文地址】