| openchat | 您所在的位置:网站首页 › OpenChat官网 › openchat |
openchat
|
似乎潜力很大,只有很少的中文数据,但是ceval,cmmlu评测效果还挺高的
图片 Model# ParamsAverageMT-BenchHumanEvalBBH MCAGIEvalTruthfulQAMMLUGSM8KBBH CoTOpenChat-3.5-12107B63.87.7668.949.548.061.865.377.361.8OpenChat-3.57B61.67.8155.547.647.459.164.377.363.5ChatGPT (March)*?61.57.9448.147.647.157.767.374.970.1OpenHermes 2.57B59.37.5448.249.446.557.563.873.559.9OpenOrca Mistral7B52.76.8638.449.442.945.959.359.158.1Zephyr-β^7B34.67.3422.040.639.040.839.85.116.0Mistral7B-6.8430.539.038.0-60.152.2-请注意本模型没有针对性训练中文(中文数据占比小于0.1%)。ceval ModelAvgSTEMSocial ScienceHumanitiesOthersChatGPT54.452.961.850.953.6OpenChat47.2945.2252.4948.5245.08cmmlu-5shot ModelsSTEMHumanitiesSocialSciencesOtherChinaSpecificAvgChatGPT47.8155.6856.562.6650.6955.51OpenChat38.745.9948.3250.2343.2745.85
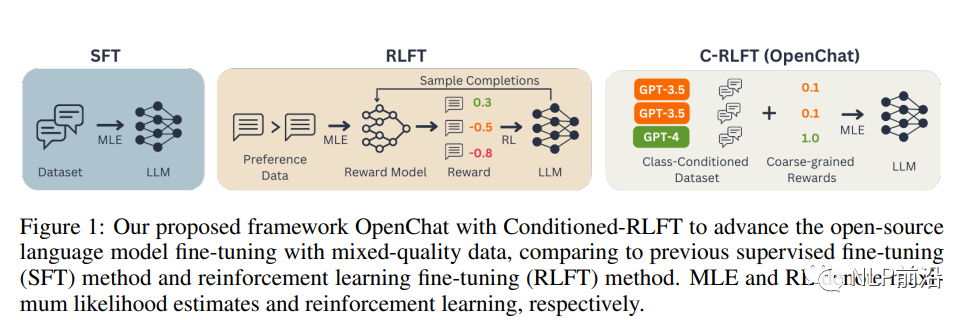
图片 首先,我们需要了解两种常见的微调方法:监督式微调(SFT)和强化学习微调(RLFT)。SFT直接使用高质量的对话数据集对预训练的语言模型进行微调,而RLFT则根据人类偏好反馈或预定义的分类器建立奖励模型,并通过强化学习最大化估计奖励。然而,这两种方法都存在局限性。SFT要求训练数据具有很高的质量,而RLFT需要昂贵的人类专家注释来收集高质量的成对或排序偏好数据。 为了解决这些问题,OpenChat框架提出了C-RLFT方法。在这个方法中,我们考虑一个通用的非成对(或非排序)SFT训练数据,包括少量的专家数据和大量的次优数据。我们将不同数据来源视为粗粒度的奖励标签,并学习一个类条件策略来利用互补的数据质量信息。有趣的是,C-RLFT中的最优策略可以通过单阶段、无需强化学习的监督学习轻松解决,从而避免了昂贵的人类偏好标签收集。 OpenChat框架包括以下几个关键步骤: 类条件数据集和奖励:根据不同的数据来源(如GPT-4和GPT-3.5),为每个示例分配类标签,并构建类条件数据集Dc。然后,根据类标签为每个示例分配粗粒度奖励。 通过C-RLFT进行微调:我们将预训练的LLM视为类条件策略πθ(y|x, c),并使用类信息增强的参考策略πc而不是原始预训练的LLM π0对其进行正则化。这样,我们可以在KL正则化的强化学习框架下优化目标函数。 模型推理:在推理阶段,我们使用与GPT-4对话相同的特定提示,以便仅生成高质量响应。 |

【本文地址】
公司简介
联系我们