| Flink的状态及状态后端 | 您所在的位置:网站首页 › Flink状态 › Flink的状态及状态后端 |
Flink的状态及状态后端
|
前言
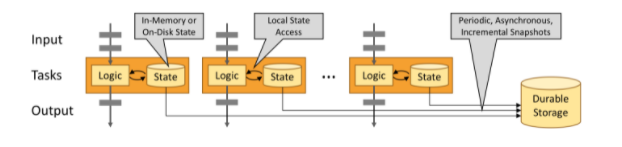
使用Flink版本 1.13 , 该版本对状态有所改变,版本变化: 删除 state.backend.async重新设计了状态后端的存储统一keyState的savePoint的存储格式为二进制FailureRateRestartBackoffTimeStrategy 允许比配置少重启一次支持未对齐检查点的重新调整:从未对齐检查点恢复的时候支持改变作业的并行度 什么是状态?对我们进行记住多个event的操作的时候,比如说窗口,那么我们称这种操作是有状态的,是需要缓存数据的。Flink 需要知道状态,以便使用检查点 和保存点使其容错 。简单的说就是Flink的一个存储单元。 从 Flink 1.11 开始,检查点可以在对齐或不对齐的情况下进行。 状态分为两种:键值状态(KeyState)和(OperatorState)非键值状态(算子状态)。 状态和ck的关系State一般指一个具体的task/operator的状态。而Checkpoint则表示了一个Flink Job,在一个特定时刻的一份全局状态快照(state snapshots ),即包含了所有task/operator的状态。 什么是状态后端Flink 提供了不同的状态后端,用于指定状态的存储方式和位置。默认情况下,配置文件flink-conf.yaml确定所有 Flink 作业的状态后端。 对于流处理程序,Flink Job的状态后端决定了它的状态如何 存储在每个 TaskManager(TaskManager 的 Java 堆或(嵌入式)RocksDB)上。 State 始终在本地访问(只是访问/使用),这有助于 Flink 应用程序实现高吞吐量和低延迟。您可以选择将状态保留在 JVM 堆上,或者如果它太大,则保留在有效组织的磁盘数据结构中,这取决于状态后端的配置。
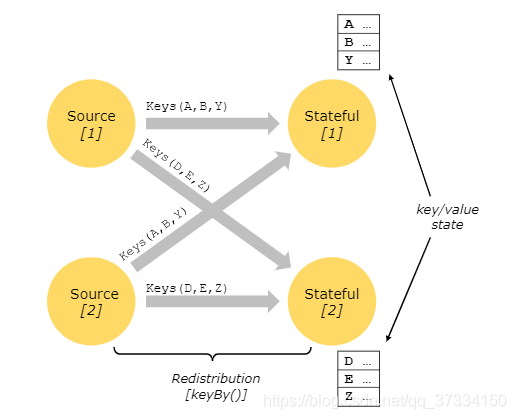
官方提供了两种静态的(开箱即用)的状态后端: HashMapStateBackend:保存数据在内部作为Java堆的对象。EmbeddedRocksDBStateBackend:在RocksDB数据库中保存动态数据。 通过状态快照的容错 #1.13版本Flink社区重新设计了状态后端的存储,以便于用户更好的理解状态后端的存储跟检查点的存储的分离。 Flink详解Exactly-Once机制注意:该文写于1.12的flink版本,那个时候ck存储和状态存储在理解上还是绑定在一起,具体情况看本文的状态后端一节。 Keyed State如果要使用键控状态,则需要先分出键控流:dataStream.keyBy()产生一个键控流(KeyedStream),然后允许使用键控状态的操作。
在上图中:Keyed State 被进一步组织成所谓的Key Groups。Key Groups的数量与定义的并行度一样多。在运行并行实例中的一个并行算子的时候,使用到一个或多个Key Groups的keys。 可用的KeydeState ValueState:保留一个可以更新和检索的值:设置update(T)和T value();ListState:保留一个元素列表,可以追加、遍历Iterable和覆盖:add(T) , addAll(List) , Iterable Iterable get() , update(List);ReducingState:只保留一个值,但是这个值代表添加到State的所有值的聚合,故为reduce。AggregatingState:只保留一个值,但是这个值代表添加到State的所有值的聚合。与ReducingState不同的是,IN的元素可能会不一样。MapState:保留一个Map,可以增加(put(UK, UV),putAll(Map)),检索(get(UK)),遍历(entries()->key()和value())和判空(isEmpty());所有类型的状态也有一个方法clear()可以清除当前活动键的状态,即输入元素的key。 我们要记住两件事1、重要的是要记住,这些状态对象仅用于与状态接口。状态不一定存储(状态后端)在内部,但可能驻留在磁盘或其他地方。 2、我们从状态(存储)获取的value,取决于event element流数据的key。流式数据是流动的。 KeydeState的使用要获得状态句柄(使用State),我们必须创建一个StateDescriptor。StateDescriptor包含了: State的名称保存的值的类型可能的用户-指定的函数,例如ReduceFunction我们可以对于上面可用的KeyedState来创建对于的StateDescriptor。我们以官网的例子来示例: 代码创建了一个统计每两个element的平均数的计数窗口,计数到2变求出平均值并清空ValueState:clear()。 public class CountWindowAverage extends RichFlatMapFunction { /** * The ValueState handle. The first field is the count, the second field a running sum. */ private transient ValueState sum; @Override public void flatMap(Tuple2 input, Collector out) throws Exception { // access the state value Tuple2 currentSum = sum.value(); // update the count currentSum.f0 += 1; // add the second field of the input value currentSum.f1 += input.f1; // update the state sum.update(currentSum); // if the count reaches 2, emit the average and clear the state if (currentSum.f0 >= 2) { out.collect(new Tuple2(input.f0, currentSum.f1 / currentSum.f0)); sum.clear(); } } @Override public void open(Configuration config) { ValueStateDescriptor descriptor = new ValueStateDescriptor( "average", // the state name TypeInformation.of(new TypeHint() {}), // type information Tuple2.of(0L, 0L)); // default value of the state, if nothing was set sum = getRuntimeContext().getState(descriptor); } } // this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env) env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L)) .keyBy(value -> value.f0) .flatMap(new CountWindowAverage()) .print(); // the printed output will be (1,4) and (1,5) // 输出两个是因为输入5个 |
【本文地址】