| 非关系型数据库 入门简介 | 您所在的位置:网站首页 › CDDI数据库是什么 › 非关系型数据库 入门简介 |
非关系型数据库 入门简介
|
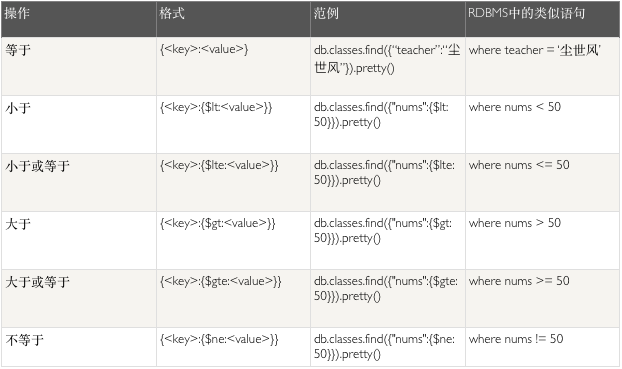
非关系型数据库也叫Nosql数据库,全称是not noly sql非关系型数据库提出另一种理念,例如,以键值对存储,且结构不固定,每一个元组可以有不一样的字段,每个元组可以根据需要增加一些自己的键值对,这样就不会局限于固定的结构,可以减少一些时间和空间的开销。使用这种方式,用户可以根据需要去添加自己需要的字段,这样,为了获取用户的不同信息,不需要像关系型数据库中,要对多表进行关联查询。仅需要根据id取出相应的value就可以完成查询。 关系型数据库与非关系型数据库的区别:关系型数据库通过外键关联来建立表与表之间的关系,非关系型数据库通常指数据以对象的形式存储在数据库中,而对象之间的关系通过每个对象自身的属性来决定。 ?♂️nosql数据库的特点: 模式自由 不需要定义表结构,数据表中的每条记录都可能有不同的属性和格式。逆规范化 不遵循范式要求,去掉完整性约束,减少表之间的依赖弹性可扩展 可在系统运行的过程中,动态的删除和增加节点。多副本异步复制 数据快速写入一个节点,其余节点通过读取写入的日志来实现异步复制。弱事务 不能完全满足事务的ACID特性,但是可以保证事务的最终一致性。 ?♂️什么时候用nosql数据库: 数据库表schema经常变化数据库表字段是复杂数据类型高并发数据库请求海量数据的分布式存储 ?♂️常见的关系型数据库有哪些: MySQLOracleDB2Microsoft SQL Serve 等 关系型数据库 关系型数据库的特性 1、关系型数据库,是指采用了关系模型来组织数据的数据库; 2、关系型数据库的最大特点就是事务的一致性; 3、简单来说,关系模型指的就是二维表格模型,而一个关系型数据库就是由二维表及其之间的联系所组成的一个数据组织。 关系型数据库的优点 1、容易理解:二维表结构是非常贴近逻辑世界一个概念,关系模型相对网状、层次等其他模型来说更容易理解; 2、使用方便:通用的SQL语言使得操作关系型数据库非常方便; 3、易于维护:丰富的完整性(实体完整性、参照完整性和用户定义的完整性)大大减低了数据冗余和数据不一致的概率; 4、支持SQL,可用于复杂的查询。 关系型数据库的缺点 1、为了维护一致性所付出的巨大代价就是其读写性能比较差; 2、固定的表结构; 3、高并发读写需求; 4、海量数据的高效率读写; ?♂️常见的nosql数据库有哪些: MongoDBNoSqlRedisMemcachedHBase 等 非关系型数据库 非关系型数据库的特性 1、使用键值对存储数据; 2、分布式; 3、一般不支持ACID特性; 4、非关系型数据库严格上不是一种数据库,应该是一种数据结构化存储方法的集合。 非关系型数据库的优点 1、无需经过sql层的解析,读写性能很高; 2、基于键值对,数据没有耦合性,容易扩展; 3、存储数据的格式:nosql的存储格式是key,value形式、文档形式、图片形式等等,文档形式、图片形式等等,而关系型数据库则只支持基础类型。 非关系型数据库的缺点 1、不提供sql支持,学习和使用成本较高; 2、无事务处理,附加功能bi和报表等支持也不好; Mongodb➡️Mongodb简介 MongoDB.inc 公司研发的一款免费开源的跨平台 NoSQL 数据库,命名源于英文单词 humongous,意思是「巨大无比」,可见开发组对 MongoDB 的定位。与关系型数据库不同,MongoDB 的数据以类似于 JSON 格式的二进制文档存储: { name: "Angeladady", age: 18, hobbies: ["Steam", "Guitar"] } 功能强大、使用灵活、性能卓越且易于扩展的数据库。文档型的数据存储方式有几个重要好处:文档的数据类型可以对应到语言的数据类型,如数组类型(Array)和对象类型(Object);文档可以嵌套,有时关系型数据库涉及几个表的操作,在 MongoDB 中一次就能完成,可以减少昂贵的连接花销;文档不对数据结构加以限制,不同的数据结构可以存储在同一张表。 MongoDB 的文档数据模型和索引系统能有效提升数据库性能;复制集功能提供数据冗余,自动化容灾容错,提升数据库可用性;分片技术能够分散单服务器的读写压力,提高并发能力,提升数据库的可拓展性。MongoDB 高性能,高可用性、可扩展性等特点,使其至 2009 年发布以来,逐渐被认可,并被越来越多的用于生产环境中。AWS、GCP、阿里云等云平台都提供了十分便捷的 MongoDB 云服务。 官方网站:https://www.mongodb.org开源项目:http://github.com/mongodb ➡️Mongodb特点 面向集合存储,易存储对象类型的数据模式自由支持动态查询支持完全索引,包含内部对象支持查询支持复制和故障恢复使用高效的二进制数据存储,包括大型对象(如视频等)自动处理碎片,以支持云计算层次的扩展性支持RUBY,PYTHON,JAVA,C++,PHP等多种语言文件存储格式为BSON(一种JSON的扩展)可通过网络访问➡️Mongodb安装 1、到官网下载mongodb压缩包或安装包,解压或安装后,可以把 bin 目录添加到环境变量,方便后续命令的执行2、在/usr/local目录下创建一个mongodb文件夹,然后把mongodb的安装包解压到mongodb文件中3、创建一个存放数据的文件夹data和日志文件logs cd /usr/local/mongodbmkdir datatouch logs4、启动mongodb /usr/local/mongodb/bin/mongod --dbpath=/usr/local/mongodb/data --logpath=/usr/local/mongodb/logs --logappend --port=27017 --fork➡️Mongodb启动参数和启动脚本 使用Mongodb安装目录下的mongod文件来启动mongodb常用的启动参数:--dbpath的意思是指定存储数据的文件夹 --logpath的意思是指定日志存储文件 --logappend的意思是日志以增加方式产生 --port指定端口,如果不写的话,默认是27017 --fork 代表后台运行 如果不打算把 mongodb 的命令放到环境变量,可以将常用命令复制到 bin 目录,方便调用,如 mongo 和 mongod。也可以把这些参数编写到一个配置文件的脚本,如副本集的启动脚本,然后读取配置文件➡️Mongodb启动脚本 启动脚本:#!/bin/bash pid=`ps -ef|grep /usr/local/mongodb/bin/mongod|grep -v "grep" | awk '{print $2}'` if [ $pid ] then echo "mongodb is running..." else /usr/local/mongodb/bin/mongod --dbpath=/usr/local/mongodb/data --logpath=/usr/local/mongodb/logs --logappend --port=27017 --fork echo 'mongodb started!' fi ➡️停止mongodb和停止脚本 Mongodb停止的时候不能直接kill掉,如果kill掉的话,下次启动会有问题停止mongodb的时候要用mongod 后面加上shutdown参数,并且指定数据库文件停止脚本#!/bin/bash pid=`ps -ef|grep /usr/local/mongodb/bin/mongod |grep -v "grep" | awk '{print $2}'` if [[ $pid ]] then /usr/local/mongodb/bin/mongod --shutdown --dbpath /usr/local/mongodb/data/ echo 'mongodb stoped' else echo "mongodb is not running..." fi ➡️重启mongodb和重启脚本 重启的过程就是先停止,后启动,我们已经写好了启动的脚本和停止的脚本,依次调用即可#!/bin/bash/usr/local/mongodb/stop_mongodb.sh/usr/local/mongodb/start_mongodb.sh➡️配置文件启动实例 相比设定选项来启动实例,通过配置文件启动更具有可维护性。在 conf 目录下新建一个配置文件: vi conf/mongodb.conf配置文件使用 = 的格式。接下来,把刚才的启动配置输入到配置文件中: port = 12345 dbpath = data logpath = log/mongodb.log fork = true启动之前别忘了先杀掉之前启动的实例kill -2 ,然后再重新启动 mongoDB: mongod -f conf/mongodb.conf在没有指定接口时,默认启动在 27017 端口。在配置的时候使用绝对路径替代相对路径,有利于在排查故障时查找 mongoDB 进程启动的目录。 ➡️连接mongodb Linux下可以直接使用mongo进入mongod命令行操作 mongo [options] [db address] [file names]之前启动实例的是在本地 12345 端口,安全模式未被开启,所以不需要输入用户名和密码即可直接连接: mongo 127.0.0.1:12345或者通过--host和--port选项指定主机和端口。一切顺利的话,就进入了 mongoDB shell,shell 会报出一连串权限警告,不过不用担心,这并不会影响之后的操作。在添加授权用户和开启认证后,这些警告会自动消失。 ➡️Mongodb的CRUD 操作 概念: 集合==表 文档==数据命令关键词: Show dbs:查看数据库Show collectios:查看集合Create collection:创建一个集合use:切换数据库insert:插入数据Find:查找数据Update:修改数据Remove:删除数据在进行增查改删操作之前,先了解下常用的 shell 操作: db 显示当前所在数据库,默认为 test show dbs 列出可用数据库 show tables show collections 列出数据库中可用集合 use 用于切换数据库 mongoDB 预设有两个数据库,admin 和 local,admin 用来存放系统数据,local 用来存放该实例数据,在副本集中,一个实例的 local 数据库对于其它实例是不可见的。使用 use 命令切换数据库: > use admin > use local > use newDatabase可以 use 一个不存在的数据库,当你存入新数据时,mongoDB 会创建这个数据库: > use newDatabase > db.newCollection.insert({x:1}) WriteResult({ "nInserted" : 1 })以上命令向数据库中插入一个文档,返回 1 表示插入成功,mongoDB 自动创建 newCollection 集合和数据库 newDatabase。下面将开始进行正式的增查改删操作。 ➡️Mongodb创建和删除数据库 Mongodb中使用use关键字来创建一个数据库use chenshifeng;#创建了一个数据库db;#查看当前的数据库db.dropDatabase(); ➡️插入数据 Mongodb中使用insert关键字来插入数据 db.collectios.insert(doc);创建一个chenshifeng库,插入一条班级信息use chenshifeng;db.classes.insert({"name":"尘世风","nums":100,"course":["mysql","linux","性能测试项目实战","性能调优","安全测试"],"teacher":"尘世风"});也可以通过定义变量的方式来插入数据new_class=({"name":"尘世风","nums":150,"course":['mysql','nosql','linux','前端性能测试'],"teacher":"尘"});db.classes.insert(new_class); MongoDB 提供 insert 方法创建新文档: db.collection.inserOne() 插入单个文档 WriteResult({ "nInserted" : 1 }) db.collection.inserMany() 插入多个文档 db.collection.insert() 插入单条或多条文档 这里以 insert 方法为例: > db.drivers.insert({name:"Chen1fa",age:18}) > db.drivers.insert({name:"Xiaose",age:35}) > db.drivers.insert({_id:91,name:"Sun1feng",age:34}) 要注意,age:18和age:"18"是不一样的,前者插入的是数值,后者插入的是字符串。插入新文档如果未指定 _id, mongoDB 会自动为插入的文档添加 _id 字段。使用 db.dirvers.find() 命令即可看到刚刚插入的文档: > db.dirvers.find() { "_id" : ObjectId("598964bd56b8c69ae1e5f36a"), "name" : "Chen1fa", "age" : 18 } { "_id" : ObjectId("598964d456b8c69ae1e5f36b"), "name" : "Xiaose", "age" : 35 } { "_id" : 91, "name" : "Sun1feng", "age" : 34 }➡️更新数据 Mongodb中使用update关键字来更新数据,db.collectios.update({条件},{更新的值})把刚才插入的乔巴班的信息加一个状态,status,上课中use chenshifeng;所有字段加全 db.classes.update({"name":"尘世风"},{"name":"尘世风","nums":100,"course":["mysql","linux","性能测试项目实战","性能调优","安全测试"],"teacher":"尘世风","status":"上课中"});$set方式只更新指定的字段 db.classes.update({"name":"尘世风"},{$set:{"createtime":"20150810"}});更新所有匹配的值 db.classes.update({"teacher":"chenshifeng"},{$set:{"teacher":"niuhy"}},{multi:true});如果更新的值不存在的话,插入一条 db.classes.update({"teacher":"fengluo"},{$set:{"teacher":"niuhy"}},{upsert:true});$inc,在原来的值上增加值,只适用于数字型 db.classes.update({"name":"尘世风"},{$inc:{"nums":20}}); MongoDB 提供 updata 方法更新文档: db.collection.updateOne() 更新最多一个符合条件的文档 db.collection.updateMany() 更新所有符合条件的文档 db.collection.replaceOne() 替代最多一个符合条件的文档 db.collection.update() 默认更新一个文档,可配置 multi 参数,跟新多个文档 以 update() 方法为例。其格式: > db.collection.update( , , { upsert: , multi: } ) 各参数意义: query 为查询条件 update 为修改的文档 upsert 为真,查询为空时插入文档 multi 为真,更新所有符合条件的文档 下面的命令将 name 字段为 Chen1fa 的文档,更新 age 字段为 30: > db.drivers.update({name:"Chen1fa"},{name:"Chen1fa", age:30}) 要注意的是,如果更新文档只传入 age 字段,那么文档会被更新为{age: 30},而不是{name:"Chen1fa", age:30}。 要避免文档被覆盖,需要用到 set指令,set 仅替换或添加指定字段: > db.drivers.update({name:"Chen1fa"},{$set:{age:30}}) 如果要在查询的文档不存在的时候插入文档,要把 upsert 参数设置真值: > db.drivers.update({name:"Alen"},{age:24},{upsert: true}) update 方法默认情况只更新一个文档,如果要更新符合条件的所有文档,要把 multi 设为真值,并使用 $set 指令: > db.drivers.update({age:{$gt:25}},{$set:{license:'A'}},{multi: true}) > db.drivers.update({age:{$lt:25}},{$set:{license:'C'}},{multi: true}) 最终结果: > db.dirvers.find() { "_id" : ObjectId("598964bd56b8c69ae1e5f36a"), "name" : "Chen1fa", "age" : 30, "license" : "A" } { "_id" : ObjectId("598964d456b8c69ae1e5f36b"), "name" : "Xiaose", "age" : 35, "license" : "A" } { "_id" : 91, "name" : "Sun1feng", "age" : 34, "license" : "A" } { "_id" : ObjectId("598968b3ed1eccef17e79abe"), "age" : 24, "license" : "C" }➡️查询数据 Mongodb中使用find关键字来查询数据,db.collectios.find();db.collectios.find();查询所有的数据db.collectios.find().pretty();已格式化的方式显示数据db.collectios.find({"xx":"xx“});#指定条件查询db.collectios.find({条件1,条件2})#and操作db.collectios.find({$or,[{条件1},{条件2}]})#or操作db.collectios.find({条件1},$or[{条件2},{条件3}]);#and和or合用db.collectios.find().count();#查询所有的行数db.collectios.find().sort(KEY:1)#排序 MongoDB 提供 find 方法查找文档,第一个参数为查询条件: > db.drivers.find() #查找所有文档 { "_id" : ObjectId("598964bd56b8c69ae1e5f36a"), "name" : "Chen1fa", "age" : 18 } { "_id" : ObjectId("598964d456b8c69ae1e5f36b"), "name" : "Xiaose", "age" : 35 } { "_id" : 91, "name" : "Sun1feng", "age" : 34 } > db.drivers.find({name: "Xiaose"}) #查找 name 为 Xiaose 的文档 { "_id" : ObjectId("598964d456b8c69ae1e5f36b"), "name" : "Xiaose", "age" : 35 } > db.drivers.find({age:{$gt:20}}) #查找 age 大于 20 的文档 { "_id" : ObjectId("598964d456b8c69ae1e5f36b"), "name" : "Xiaose", "age" : 35 } { "_id" : 91, "name" : "Sun1feng", "age" : 34 } 上述代码中的$gt对应于大于号>的转义。第二个参数可以传入投影(projection,投影仪中,白色光源通过分光镜、 液晶板、投影镜头的光学变换后,投射到反射面上,显示出了彩色图像)文档映射数据: > db.drivers.find({age:{$gt:20}},{name:1}) { "_id" : ObjectId("598964d456b8c69ae1e5f36b"), "name" : "Xiaose" } { "_id" : 91, "name" : "Sun1feng" } 上述命令将查找 age 大于 20 的文档,返回 name 字段,排除其它字段。投影文档中字段为 1 或真值表示包含,0 或假值表示排除, 可以设置多个字段为 1 或 0,但不能混合使用。 除此之外,还可以通过 count、skip、limit 等指针(Cursor)方法,改变文档查询的执行方式: > db.drivers.find().count() #统计查询文档数目 3 > db.drivers.find().skip(1).limit(10).sort({age:1}) { "_id" : 91, "name" : "Sun1feng", "age" : 34 } { "_id" : ObjectId("598964d456b8c69ae1e5f36b"), "name" : "Xiaose", "age" : 35 } 上述查找命令跳过 1 个文档,限制输出 10 个,以 name 子段正序排序(大于 0 为正序,小于 0 位反序)输出结果。 最后,可以使用 Cursor 方法中的 pretty 方法,提升查询文档的易读性,特别是在查看嵌套的文档和配置文件的时候: > db.drivers.find().pretty()➡️Mongodb中的条件表达式
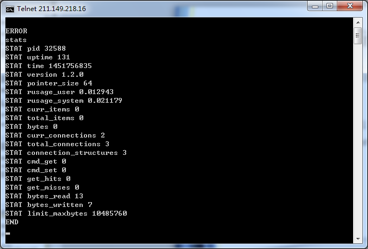
➡️删除数据 Mongodb中使用remove关键字来删除数据,db.collectios.remove();db.collectios.remove({});删除所有的数据db.collections.remove({条件1},1)#如果有多条匹配的,只删除一条 MongoDB 提供了 delete 方法删除文档: db.collection.deleteOne() 删除最多一个符合条件的文档 db.collection.deleteMany() 删除所有符合条件的文档 db.collection.remove() 删除一个或多个文档 以 remove 方法为例: > db.drivers.remove({name:"Xiaose"}) #删除所有 name 为 Xiaose 的文档 > db.drivers.remove({age:{$gt:30}},{justOne:true}) #删除所有 age 大于 30 的文档 > db.drivers.find() { "_id" : ObjectId("598964bd56b8c69ae1e5f36a"), "name" : "Chen1fa", "age" : 30, "license" : "A" } { "_id" : ObjectId("598968b3ed1eccef17e79abe"), "age" : 24, "license" : "C" } MongoDB 提供了 drop 方法删除集合,返回 true 表面删除集合成功: > db.drivers.drop()➡️开启profile Mongodb的profile就和mysql的慢查询类似,用于记录执行时间超过多少的语句。db.getProfilingLevel()#获取profile级别db.setProfilingLevel(1,2000)# 设置profile级别profile级别有三种: 0:不开启1:记录慢命令,默认为大于100ms2:记录所有命令查询profile记录 db.system.profile.find();ts: 该命令在何时执行 op: 操作类型 query: 本命令的详细信息 responseLength: 返回结果集的大小 ntoreturn: 本次查询实际返回的结果集 millis: 该命令执行耗时,以毫秒记➡️创建索引 db.collections.ensureIndex({xx:1})#创建单列索引db.collections.ensureIndex({xx:1,xx:1})#创建多列索引db.collections.ensureIndex({xx:1},{“unique”:true})#创建唯一索引➡️查看、删除索引 db.system.indexes.find();查看索引db.collections.getIndexes();#查看当前集合中的索引Mongodb中使用dropIdenx来删除索引db.collections.dropIndex({xx:1});删除指定索引db.user.dropIndexes();删除所有的索引➡️explain 使用explain可以解析查询语句db.collection.find({xx:xx}).explain();Explain说明: cursor: 返回游标类型(BasicCursor 或 BtreeCursor)nscanned: 被扫描的文档数量n: 返回的文档数量millis: 耗时(毫秒)indexBounds: 所使用的索引isMultiKey:是否使用了多键索引 scanAndOrder:是否在内存中对结果集进行了排序 indexOnly:是否只使用索引就能完成查询(覆盖索引) 相比传统关系型数据库,MongoDB 的 CURD 操作更像是编写程序,更符合开发人员的直觉,不过 MongoDB 同样也支持 SQL 语言。MongoDB 的 CURD 引擎配合索引技术、数据聚合技术和 JavaScript 引擎,赋予 MongoDB 用户更强大的操纵数据的能力。 关闭实例关闭 mongoDB 服务: > use admin > db.shutdownServer()使用 exit 或 Ctrl + C 断开连接: > exit上述,我们启动了一个不安全的 MongoDB 实例,应用到生产环境中,还需要了解 MongoDB 的安全机制,了解如何建立索引提升数据库的读写速度。随着数据的增长,需要了解副本集技术如何将多个实例部署到不同的服务器、了解分片技术对数据库进行横向扩展。为保证服务器性能和安全,需要了解如何对 MongoDB 进行测试和监控… Redis➡️Redis简介 redis是一个开源的、使用C语言编写的、支持网络交互的、可基于内存也可持久化的Key-Value数据库。redis的官网地址,非常好记,是redis.io。Redis和mongodb的区别是redis数据全部存储在内存中,使用磁盘仅用于数据的持久化,而mongodb数据是存储在磁盘上。➡️Redis安装 1、下载redis安装包wget http://download.redis.io/releases/redis-2.8.12.tar.gz 2、安装redis依赖yum -y install gcc* yum -y install make yum -y install tcl 3、编译安装tar xvf redis-2.8.12.tar.gz mv redis-2.8.12 redis #改名 mv redis /usr/local #移动 cd /usr/local/redis make 4、使用redis的可执行命令将redis命令移动到/usr/local/bin目录下,把redis命令放到/usr/local/bin目录下后就可以直接使用redis命令,如果不放到/usr/local/bin也是可以的,直接到/usr/local/redis/src目录下使用即可。 cd /usr/local/redis/src cp -rf redis-benchmark redis-server redis-cli redis-check-dump redis-check-aof /usr/local/bin ➡️Redis启动 启动redis 介绍两种启动方式,一种是命令启动,一种是使用配置文件启动。redis-server & #这种是命令启动,默认端口6379,&表示后台运行redis-server /usr/local/redis/redis.conf #配置文件启动的,可以在配置文件中修改端口 由于redis默认带的配置文件不是后台运行的,咱们不用它,新建一个redis.conf配置文件,把原来那个默认的删掉,新的配置文件内容如下: daemonize yes #代表后台启动 pidfile /usr/local/redis/redis.pid #pid文件 logfile /usr/local/redis/redis.log #日志文件 port 6379#端口 dir /usr/local/redis/redisData #持久化文件存放位置➡️Redis启动脚本 为了方便管理,现在写一个redis的启动脚本和停止脚本启动脚本:#!/bin/bash pid=`ps -ef|grep redis-server|grep -v "grep"|awk '{print $2}'` if [[ "$pid" ]] then echo "redis is running...." else /usr/local/bin/redis-server /usr/local/redis/redis.conf echo "redis started!“ ➡️Redis停止脚本 停止脚本: #!/bin/bashpid=`cat /usr/local/redis/redis.pid`new_pid=`ps -ef|grep pid|grep -v "grep"|awk '{printpid|grep -v "grep"|awk '{print2}'`if [[ $new_pid ]]thenkill -9 $pidecho "redis is stoped!"elseecho "redis is not running..."fi➡️Redis重启脚本 重启脚本,重启不过就是先停止,后启动,我们已经写好停止和启动的脚本,依次调用即可: #!/bin/bash/usr/local/redis/stop_redis/usr/local/redis/start_redis➡️连接redis Linux下可以直接使用redis-cli进入redis命令行操作 ➡️Redis的增删改查 选择数据库,使用select关键字 select 1,选择第一个数据库使用set关键字插入数据 set name andashu使用get 关键字获取数据 get name使用del 关键字 删除数据 del name Memcached➡️Memcached简介 Memcached是一个高性能的分布式的内存对象缓存系统,目前全世界不少人使用这个缓存项目来构建自己大负载的网站,来分担数据库的压力,通过在内存里维护一个统一的巨大的hash表,它能够用来存储各种格式的数据,包括图像、视频、文件以及数据库检索的结果等。简单的说就是将数据调用到内存中,然后从内存中读取,从而大大提高读取速度。➡️Memcached安装 1、安装依赖包libeventyum -y install libevent 2、编译安装tar xvf memcached-1.2.0.tar.gz cd memcached-1.2.0 ./configure --prefix=/usr/local/memcached make make install ➡️Memcached启动参数 -p 监听的端口-c 最大同时连接数,默认是1024 -m 最大内存使用,单位MB。默认64MB-P 设置保存Memcache的pid文件-d 后台运行-u 运行Memcache的用户,仅在以root运行的时候有效➡️Memcached启动脚本 #!/bin/bashpid=`ps -ef|grep memcached|grep -v "grep"|awk '{print $2}'`if [[ $pid ]]thenecho "memcached is running..."else/usr/local/bin/memcached -d -m 10 -p 11211 -u root -c 256 -P /tmp/memcached.pid >> /tmp/memcached.logecho 'memcached started pidfile path is /tmp/memcached.pid'fi➡️Memcached停止脚本 #!/bin/bashpid=`cat /tmp/memcached.pid`new_pid=`ps -ef|grep pid|grep -v "grep"|awk '{printpid|grep -v "grep"|awk '{print2}'`if [[ $new_pid ]]thenkill -9 `cat /tmp/memcached.pid`echo "memcached stoped..."elseecho "memcached is not runing...."fi➡️Memcached重启脚本 重启脚本也和前面的一样,先停止再启动#!/bin/bash/usr/local/memcached/stop_mem.sh/usr/local/memcahed/start_mem.sh➡️Memcached连接方式 Memcached没有可视化工具,只能通过Telnet这种方式来连接telnet ip 端口telnet 211.149.218.16 11211telnet上去之后,可以输入stats查看memcached信息 ➡️Memcached的增删改查 增加使用add 关键字 add key 0 存放时间 数据大小add name 0 30 5查询使用get 关键字 get keyget name修改使用set或者replace关键字,set和replace的区别是set一个不存在的key时,会新增,replace一个不存在key时,会报错。 set key 0 存放时间 数据大小replace key 0 存放时间 数据大小set name1 0 50 6replace name 0 70 5删除使用delete关键字 delete keydelete name1
|


【本文地址】