| 最小二乘支持向量机分类器(LSSVM)及Python实现 | 您所在的位置:网站首页 › 2乘2模型图 › 最小二乘支持向量机分类器(LSSVM)及Python实现 |
最小二乘支持向量机分类器(LSSVM)及Python实现
|
最小二乘支持向量机分类器
1.支持向量机分类2.最小二乘支持向量机用于分类任务3.最小二乘支持向量机用于回归4.LSSVM分析5.LSSVM的Python实现
在这篇文章中,我们讨论支持向量机(SVM)分类器的最小二乘版本。由于公式中的相等类型约束。解是由解一组线性方程得出的。而不是经典的支持向量机的二次规划。 本文针对两类分类问题,提出了支持向量机的最小二乘模型。对于函数估计问题,支持向量解释边缘回归。在(Saunders et al., 1998)中,它考虑了等式类型的约束,而不是经典的支持向量机方法中的不等式。在这里,我们也考虑了在最小二乘意义下的公式分类问题的等式约束。因此,求解直接遵循求解一组线性方程,而不是二次规划。在经典的支持向量机中,许多支持值为零(非零值对应于支持向量),而在最小二乘支持向量机中,支持值与误差成正比。 1.支持向量机分类给定N个点的训练集
(1)优化目标 这里我们将最小二乘版本引入SVM分类器,将分类问题表述为: 定义拉格朗日函数: a. 使用等式约束,而不是不等式约束; b. 由于对每个样本点采用了等式约束,因此对松弛向量不施加任何约束,这也是LSSVM丢失稀疏性的重要原因; c. 通过解决等式约束以及最小二乘问题,使得问题得到进一步简化。 3.最小二乘支持向量机用于回归
特性: 1) 同样是对原始对偶问题进行求解,但是通过求解一个线性方程组(优化目标中的线性约束导致的)来代替SVM中的QP问题(简化求解过程),对于高维输入空间中的分类以及回归任务同样适用; 2) 实质上是求解线性矩阵方程的过程,与高斯过程(Gaussian processes),正则化网络(regularization networks)和费雪判别分析(Fisher discriminant analysis)的核版本相结合; 3) 使用了稀疏近似(用来克服使用该算法时的弊端)与稳健回归(稳健统计); 4) 使用了贝叶斯推断(Bayesian inference); 5) 可以拓展到非监督学习中:核主成分分析(kernel PCA)或密度聚类; 6) 可以拓展到递归神经网络中。 缺点: (1)解决分类任务时,全部训练样本都会被作为支持向量来看待,这就会导致其丧失SVM原有的稀疏性质,但是还可以通过对训练集进行基于支持度的“减枝”(pruning)处理来达到稀疏化的目的,这一步也可以看做是一种稀疏近似(sparse approximate)操作。 (2) 5.LSSVM的Python实现 // from numpy import * def loadDataSet(filename): '''导入数据 input: filename:文件名 output:dataMat(list)样本特征 labelMat(list)样本标签 ''' dataMat = [] labelMat = [] fr = open(filename) for line in fr.readlines(): lineArr = line.strip().split('\t') dataMat.append([float(lineArr[0]),float(lineArr[1])]) labelMat.append(float(lineArr[2])) return dataMat,labelMat def kernelTrans(X,A,kTup): '''数据集中每一个数据向量与数据A的核函数值 input: X--特征数据集 A--输入向量 kTup--核函数参量定义 output: K--数据集中每一个数据向量与A的核函数值组成的矩阵 ''' X = mat(X) m,n = shape(X) K = mat(zeros((m,1))) if kTup[0] == 'lin': K = X * A.T elif kTup[0] == 'rbf': for j in range(m): deltaRow = X[j,:] - A K[j] = deltaRow * deltaRow.T K = exp(K/(-1 * kTup[1] ** 2)) else: raise NameError('Houston We Have a Problem -- That Kernel is not recognized') return K class optStruct: def __init__(self,dataMatIn,classLabels,C,kTup): self.X = dataMatIn self.labelMat = classLabels self.C = C self.m = shape(dataMatIn)[0] self.alphas = mat(zeros((self.m,1))) self.b = 0 self.K = mat(zeros((self.m,self.m))) #特征数据集合中向量两两核函数值组成的矩阵,[i,j]表示第i个向量与第j个向量的核函数值 for i in range(self.m): self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup) def leastSquares(dataMatIn,classLabels,C,kTup): '''最小二乘法求解alpha序列 input:dataMatIn(list):特征数据集 classLabels(list):分类标签集 C(float):参数,(松弛变量,允许有些数据点可以处于分隔面的错误一侧) kTup(string): 核函数类型和参数选择 output:b(float):w.T*x+b=y中的b alphas(mat):alphas序列 ''' oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,kTup) ##1.参数设置 unit = mat(ones((oS.m,1))) #[1,1,...,1].T I = eye(oS.m) zero = mat(zeros((1,1))) upmat = hstack((zero,unit.T)) downmat = hstack((unit,oS.K + I/float(C))) ##2.方程求解 completemat = vstack((upmat,downmat)) #lssvm中求解方程的左边矩阵 rightmat = vstack((zero,oS.labelMat)) # lssvm中求解方程的右边矩阵 b_alpha = completemat.I * rightmat oS.b = b_alpha[0,0] for i in range(oS.m): oS.alphas[i,0] = b_alpha[i+1,0] return oS.alphas,oS.b,oS.K def predict(alphas,b,dataMat,testVec): '''预测结果 input:alphas(mat):Lagrange乘子序列 b(float):分隔超平面的偏置 dataMat() output:sign(float(predict_value))(int):预测样本的类别 ''' Kx = kernelTrans(dataMat,testVec,kTup) #可以对alphas进行稀疏处理找到更准确的值 predict_value = Kx.T * alphas + b # print('预测值为:%f'%predict_value) # print('分类结果为:%f'%sign(float(predict_value))) return sign(float(predict_value)) if __name__ == '__main__': ##1.导入数据 print('-----------------------------1.Load Data-------------------------------') dataMat,labelMat = loadDataSet('testSetRBF.txt') C = 0.6 k1 = 0.3 kernel = 'rbf' kTup = (kernel,k1) ##2.训练模型 print('----------------------------2.Train Model------------------------------') alphas,b,K = leastSquares(dataMat,labelMat,C,kTup) ##3.计算训练误差 print('----------------------------3.Calculate Train Error--------------------') error = 0.0 for i in range(len(dataMat)): test = predict(alphas,b,dataMat,dataMat[i]) if test != float(labelMat[i]): error +=1.0 errorRate = error/len(dataMat) print('---------------训练误差为:%f-------------------'%errorRate)参考: 文章 源码 博客 |
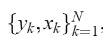 ,Xk是第K个输入模式,Yk是第K个输出模式,支持向量机方法旨在构建一种分类器:
,Xk是第K个输入模式,Yk是第K个输出模式,支持向量机方法旨在构建一种分类器: 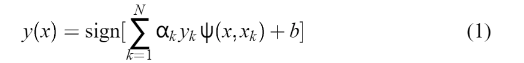 αk 是正常量,b是实常量,对于
αk 是正常量,b是实常量,对于 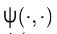 有下列选择:
有下列选择: 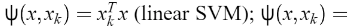
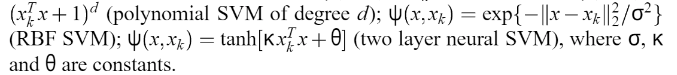 构建如下分类器: 假定
构建如下分类器: 假定 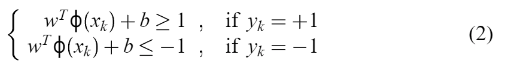 这个式子等同于
这个式子等同于 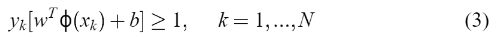
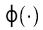 是非线性函数,它映射输入空间到更高维空间。 然而,这个函数不是显式构造的。为了有违反(3)的可能性,在这个高维空间中不存在一个分离的超平面时,引入了这样的变量
是非线性函数,它映射输入空间到更高维空间。 然而,这个函数不是显式构造的。为了有违反(3)的可能性,在这个高维空间中不存在一个分离的超平面时,引入了这样的变量 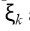
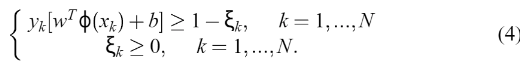 根据结构风险最小化原则,将优化问题公式化,使风险界最小化:
根据结构风险最小化原则,将优化问题公式化,使风险界最小化: 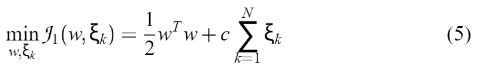 它满足(4)。同时通过引入拉格朗日乘数
它满足(4)。同时通过引入拉格朗日乘数 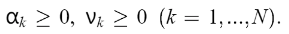 ,我们构建了拉格朗日方程
,我们构建了拉格朗日方程 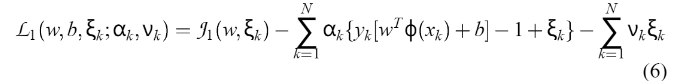 通过计算
通过计算 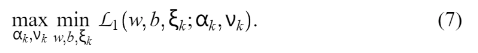 获得拉格朗日点的解。 一个解是:
获得拉格朗日点的解。 一个解是: 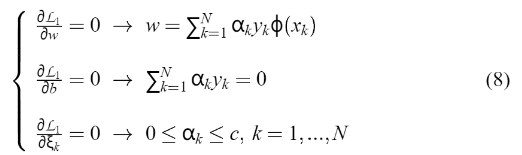 它会影响下面这个二次规划问题的答案:
它会影响下面这个二次规划问题的答案: 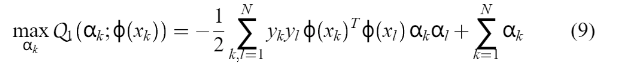 比如:
比如: 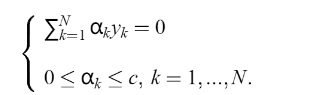
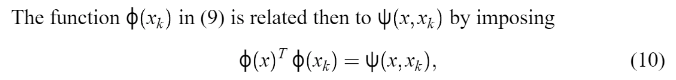 这是由默瑟定理提出的。需要注意的是,对于两层神经支持向量机,Mercer‘s ’条件仅支持K和theta 的特定参数值。 通过解决
这是由默瑟定理提出的。需要注意的是,对于两层神经支持向量机,Mercer‘s ’条件仅支持K和theta 的特定参数值。 通过解决 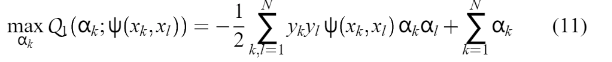 设计分类器(1),它满足(9)中的条件。为了确定决定决策面,没有计算w和ф(x)。 因为矩阵与这个二次规划问题不是无限期的,(11)的解决方案将是全局的。 并且,超平面(3)满足
设计分类器(1),它满足(9)中的条件。为了确定决定决策面,没有计算w和ф(x)。 因为矩阵与这个二次规划问题不是无限期的,(11)的解决方案将是全局的。 并且,超平面(3)满足 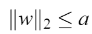 ,VC-维度h满足:
,VC-维度h满足:  [ . ]表示整数部分和r是包含点的半径最小的球中φ(x1)、…φ(xN)。通过定义拉格朗日函数就可以找到这个球
[ . ]表示整数部分和r是包含点的半径最小的球中φ(x1)、…φ(xN)。通过定义拉格朗日函数就可以找到这个球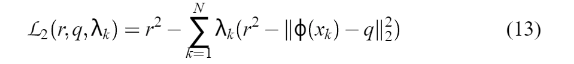 q表示球心,
q表示球心, 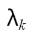 是正拉格朗日变量。 与(5)中发现与
是正拉格朗日变量。 与(5)中发现与 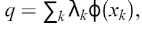 等同的球心相似的方式,从
等同的球心相似的方式,从 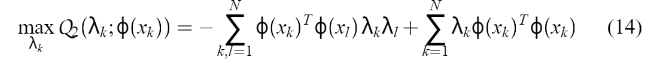 找到拉格朗日变量,其中
找到拉格朗日变量,其中 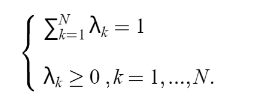 根据(10),Q2也可以表示为
根据(10),Q2也可以表示为 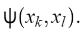 最后,通过求解(11)并从(14)中计算(12)来选择一个VC维最小的支持向量机。
最后,通过求解(11)并从(14)中计算(12)来选择一个VC维最小的支持向量机。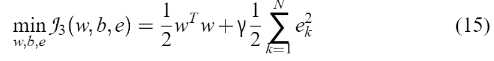 它满足平等的限制:
它满足平等的限制: 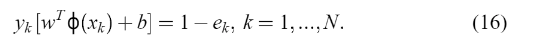 (2)拉格朗日乘子法
(2)拉格朗日乘子法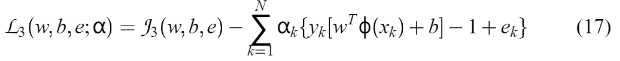 其中 aK 是拉格朗日乘数的等式约束,现在可以是正的或负的)。 (3)求解最优化条件 约束优化:
其中 aK 是拉格朗日乘数的等式约束,现在可以是正的或负的)。 (3)求解最优化条件 约束优化: 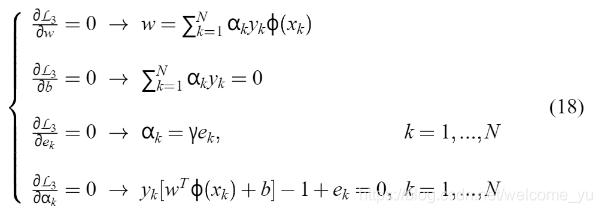 (4)求解对偶问题 上式可以直接写成以下一组线性方程的解(Fletcher, 1987):
(4)求解对偶问题 上式可以直接写成以下一组线性方程的解(Fletcher, 1987): 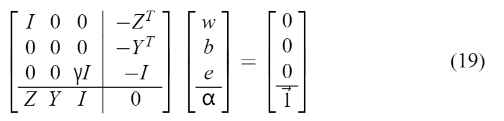
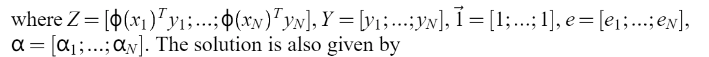
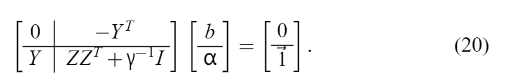 Mercer’s 的条件可以再次应用到矩阵
Mercer’s 的条件可以再次应用到矩阵 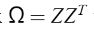 其中,
其中, 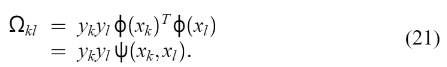 因此,分类器(1)是通过求解线性方程组(20)(21)而不是二次规划得到的。如RBF核的σ等核的参数可根据(12)进行优化选择。支持值 αk 与数据点(18)的误差成比例,而在(14)的情况下,大多数值等于零。因此,在最小二乘情况下,人们更愿意说一个支持值谱。 LLSVM通过求解上述线性方程组,得到优化变量a aa和b bb的值,这种求解方式比求解QP问题更加简便。 最小二乘支持向量机求解时,计算成本低,并且没有许多局部最小值,是一个凸优化问题的解决方案。 并且泛化性能较好。 (5)与标准SVM的区别
因此,分类器(1)是通过求解线性方程组(20)(21)而不是二次规划得到的。如RBF核的σ等核的参数可根据(12)进行优化选择。支持值 αk 与数据点(18)的误差成比例,而在(14)的情况下,大多数值等于零。因此,在最小二乘情况下,人们更愿意说一个支持值谱。 LLSVM通过求解上述线性方程组,得到优化变量a aa和b bb的值,这种求解方式比求解QP问题更加简便。 最小二乘支持向量机求解时,计算成本低,并且没有许多局部最小值,是一个凸优化问题的解决方案。 并且泛化性能较好。 (5)与标准SVM的区别
【本文地址】
| 今日新闻 |
| 推荐新闻 |
| 专题文章 |