| 浅析Unity引擎视角下的游戏内存优化 | 您所在的位置:网站首页 › 16mb是多大内存 › 浅析Unity引擎视角下的游戏内存优化 |
浅析Unity引擎视角下的游戏内存优化
|
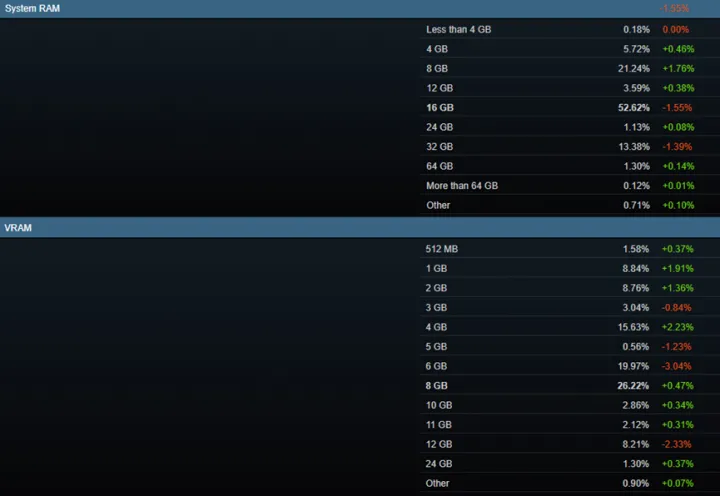
试想一个场景,你们的游戏在PC上推出后大火,领导们决定拓展一下游戏的市场,让游戏能够触及更多的平台和机型,例如手机,主机等。这时候你所在的团队接到了这样的任务,一边是制作标准极高,视觉效果高大上的游戏,另一边是性能捉鸡的新目标平台,你们需要在保留原有游戏的所有内容的同时,还要持续跟进游戏内容的更新,同时不影响到现有平台的运行。这看起来就是一个非常艰巨的任务。 假设你所在的团队已经完成了前期的跨平台移植工作,游戏已经能够在新平台跑起来了,这个时候往往会遇到的第一个问题就是内存不足。目前配备独立显卡的PC平台的可用内存,基本都是8GB以上的系统内存+3GB以上的显存,实在不够用还可以交换到磁盘上,所以一般PC端的游戏,不会特别考虑内存不足的情况。
目前PC平台主流内存/显存配置占比
而在移动端和主机端这样的平台上,可用内存往往捉襟见肘,还需要同时兼顾CPU和GPU的使用。作为一个引擎开发工程师,该如何从引擎端进行内存的优化呢?笔者认为,可以从以下几个方面考虑。 1、关注各种粗放的使用
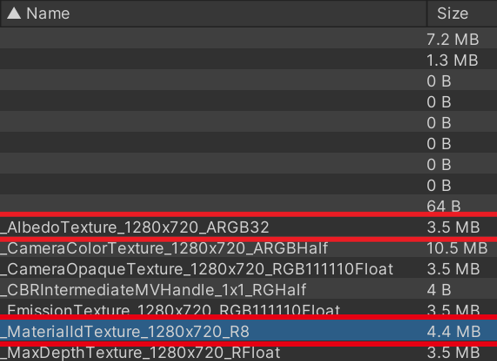
这个方法比较适合在优化的前期搞,也是比较常规的优化方法。在这个阶段仔细分析一下memory profile中的数据,往往就能看到很多“铺张浪费”的地方,可能只需稍加改动,就可以节省几百兆的内存。笔者觉得几个可以特别关注的部分: 纹理,RT在往配置较低的平台进行移植的时候,纹理上往往可以压缩出很多的空间。随着渲染分辨率的降低,纹理也可以适当降低分辨率。尤其是一些在屏幕空间上占比很小的物体、特效。在1080P分辨率下,对于有着比较复杂细节的时装,512x512的分辨率足够保持其细节;对于细节不太丰富的时装,如一些大块色块拼接的时装,256x256甚至128x128也足够了。在720P分辨率下,可以相较1080P均降一级。如果还不能满足内存要求,可以在保持主贴图(diffuse)分辨率不变的情况下,压缩其他贴图的分辨率。 RT也是一个可以压榨出许多内存的地方,可以多多留意各张RT的大小,及时发现其中不合理的地方,例如下图中,R8格式的RT居然比同样分辨率的ARGB32的大小还大,仔细研究后会发现,R8格式的RT带有depth,而这张MaterialId RT显然不需要depth buffer。
多张同分辨率的RT之间也可以尽可能复用,例如后处理阶段,往往需要多个屏幕大小的RT,后面的后处理效果就可以复用已经完成的后处理效果使用过的RT。可以实现一个全局的RT pool来对这些临时的RT进行管理,根据RT的分辨率,格式,mipmap,depth bits来计算hash,实现帧内复用的效果。同时对pool内的RT的使用情况进行统计,这样就可以自动清理长时间没有使用的RT。 压缩选项Unity3D中,一些压缩选项对内存也有着比较大的影响。比如Unity3D针对mesh提供了vertex compression和mesh compression两种压缩。其中vertex compression是可以开启的,对内存占用有一定的优化效果,代价是损失vertex的精度,实测下来精度的影响并不大;而mesh compression开启后,文件的体积会减小,但是加载到内存中占用的内存空间会增大,实测内存占用可能会相差接近一倍,因此mesh compression可以关闭。
一些容器,比如hash table,可能原先使用的key是字符串,如果容纳的东西很多的话,存储字符串就是一笔很大的开销;一些结构中可能存在一些不必要的字符串或是大体积的其他属性,可以直接去掉,以减少存储开销;有一些会被大量分配出来的struct,可以尝试去除struct的padding,也能减少一定的内存占用。 2、提高内存分配器的空间利用率
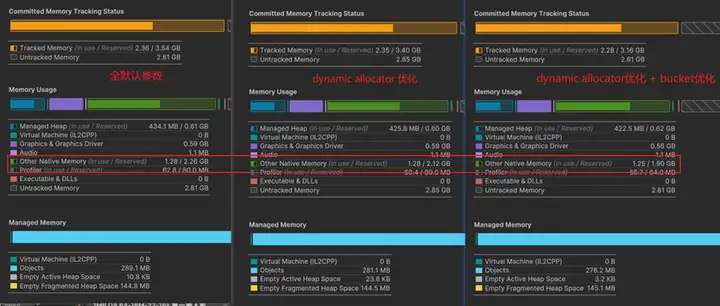
内存分配器是引擎中最常使用到的模块之一了,实际项目中,内存分配器往往要在分配性能和空间利用率上寻求平衡,因此对于内存不足的平台而言,需要特别注意内存分配器上的内存开销。如果通过memory profiler分析发现,游戏的内存分配器空间利用率很低的话,就可以考虑对内存分配器进行优化。
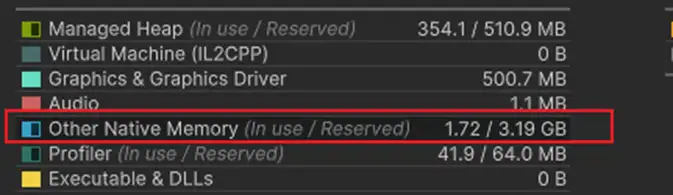
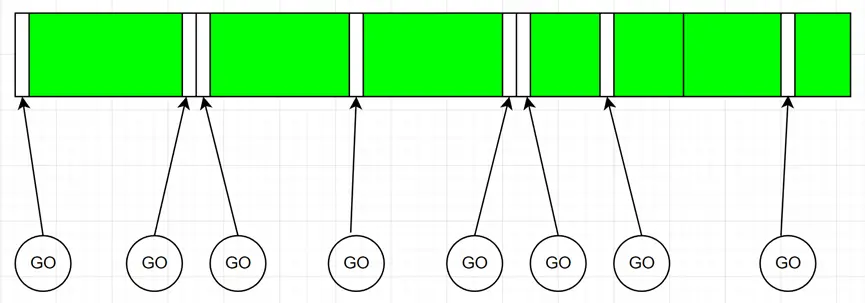
对于Unity3D而言,其用于分配persistent native memory的分配器主要是dynamic heap allocator和bucket allocator两种(具体参考Memory allocator customization)。其中bucket allocator是针对字节级别的小内存进行分配的,dynamic heap allocator则对较大的内存进行分配。Unity3D的dynamic heap allocator使用TLSF算法分配内存,TLSF算法的具体细节这里就不展开赘述了,相关源码可以查看这个repo:https://github.com/mattconte/tlsf。 简单来说,TLSF会以block的形式对内存进行管理,即先从系统申请一块较大空间的内存,再在这块空间内部进行划分以满足不同大小的内存的分配请求。通常,为了兼顾分配的性能,block的大小为数兆字节(Unity3D默认为16MB),而TLSF内部内存分配的粒度相对来说又较大,这样分配器内部就会产生一些无法利用的空间。 实际项目中,通过统计各个大小区间的内存分配数量,也可以观察到,Unity3D的native内存分配时,1k字节以下的内存分配占据了绝大多数。如果对每个block内的分配情况进行统计,也可以观察到很多block被几个几十,几百字节的对象占住无法释放的情况,大概类似这样的情形:
可以将TLSF的每个block的大小适当减小,减少这部分的内存占用。但实际测试下来,这部分的提升并不明显。这个时候就可以使用Unity3D提供的另外一个分配器:bucket allocator。Bucket allocator是一个无锁的,专门用于小内存分配的分配器,由于内存分配的粒度可以设置得比较精细,内部的碎片率会比TLSF的分配器更低一些。
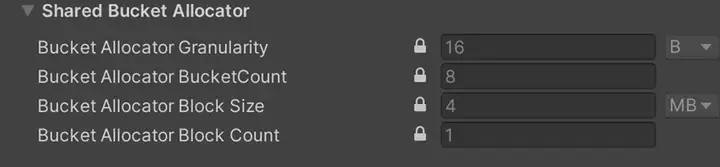
Unity3D为bucket allocator提供了分配粒度,bucket数量,block大小和数量四个配置选项,其中block的概念和TLSF的block类似,bucket allocator会一次性向系统申请一块较大的内存,再将block划分为一个个不同大小的bucket,在实际进行内存分配的时候,返回大小最贴近的bucket的地址。 Bucket的大小则由分配粒度和bucket数量共同决定,以默认的16B和8个为例,8个buckets的大小分别为:16B,32B,48B,64B,80B,96B,112B和128B。这两个参数也决定了bucket allocator能够分配的内存大小的上限,即128B。Block数量和block大小则共同决定了bucket allocator一共能够分配多少内存,以默认的4MB和1个为例,就是总共能够分配4MB的内存。超出的部分就会使用TLSF进行分配。 默认的参数对于一些很小的项目来说也许是够用的,但是在我们项目中这个设定太过保守了,实际测试下来,1k字节以下的内存分配大小可以达到400~500MB,让这部分内存使用TLSF进行分配是不划算的。通过将bucket数量设为64,bucket能够分配的总大小设成512MB后,满足了相应的要求,也减少了native内存的reserve率。
3、去GameObject
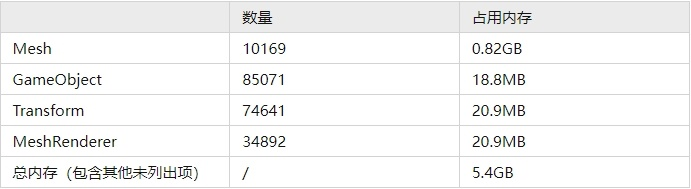
首先思考一下,一般而言,一个Unity的场景是如何组织的:美术将制作好的场景物体的FBX导入到Unity3D工程中后,还会制作对应的prefab,对LOD,材质,场景中位置等相关的一些参数进行调整;运行时,程序编写的相关逻辑会将prefab加载上来,实例化成一个个GameObject到场景中。 对于一个大型的场景而言,同时管理的GamaObject数量可能有上万个,通常会使scene streaming去管理这些GameObject,即整个场景划分为m x m的区块,以角色为中心加载周围n x n的区块,其它区域则使用HLOD。区块的加载窗口一般为5 x 5、3 x 3和1 x 1等,加载卸载可能还有更复杂的判断机制,这里不展开了。 对内存进行分析后可以看到,仅Mesh数量就高达一万多个,占据了800多MB的内存,GameObject、Transform以及MeshRenderer更是有数万个,如此众多的数量不仅会占用内存,也会使得内部的内存碎片化现象加剧,影响性能。因此,对这一部分进行优化是至关重要的。
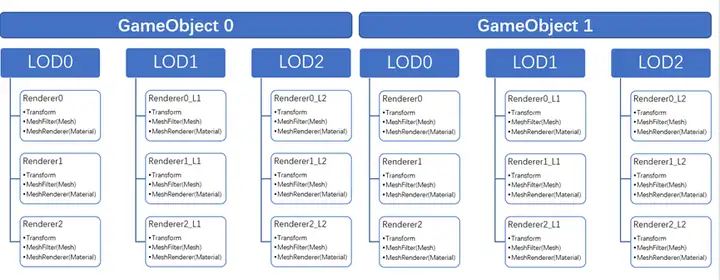
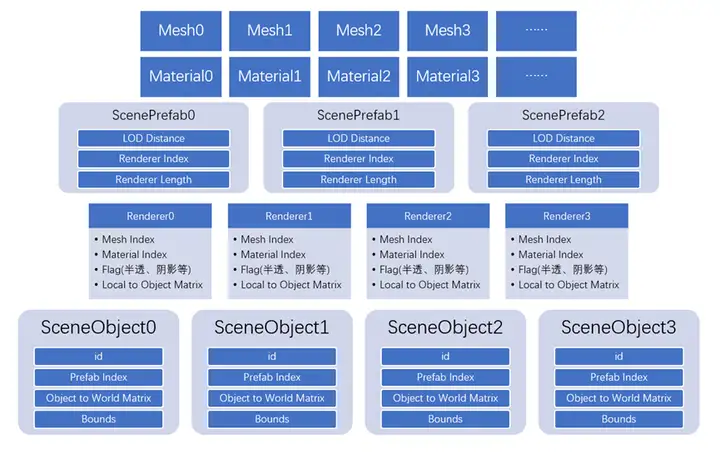
优化的方向不仅仅是减少不必要的GameObject的加载,也需要注意到,这些GameObject中,相当大的一部分都是静态的物体,对于这些静态的物体而言,实际上运行时我们仅仅只需要它们的mesh,material,以及transform数据就足够了,GameObject本身及其身上挂的component在引擎内部除了自身的内存开销之外,还有因为instanceID,依赖的bundle增加之后,导致内部一些容器被撑大的隐形开销等。 因此我们就可以从两个角度来进行优化:使用自己的管线对静态物体进行渲染,避开Unity GameObject的开销;对场景中不必要的物体进行卸载。 要做到第一点,首先需要将场景组织数据从GameObject导出到自己管理的数据结构。原本的GameObject(以prefab的形式)的组织结构如下图所示。每级LOD分别对应了多个renderer,每个renderer又有自己对应的transform,mesh和material。
我们可以分别定义RendererData,ScenePrefab和SceneObject三个结构体,将原先GameObject中的各个LOD level的renderer对应mesh和material数据单独提出到两个列表里,将对应的meshIndex,materialIndex以及transform的数据记录到RendererData中。GameObject每一级LOD包含的renderer则平铺保存到另一个RendererData 数组allRenderers里,并将各个LOD在allRenderers中对应的lodXRendererStart和lodXRendererLength记录到ScenePrefab中。最后用SceneObject替代原先的GameObject在运行时对物体进行描述,方便Scene streaming动态处理。 public struct RendererData { public int prefabIndex; public int meshIndex; public int materialIndex; public ShadowCastingMode shadowCastMode; public Unity.Mathematics.float4x4 localToObject; public short enableTransparent; } struct ScenePrefab { public int prefabValidFlag; public int lod0RendererStart; public int lod0RendererLength; public int lod1RendererStart; public int lod1RendererLength; public int lod2RendererStart; public int lod2RendererLength; public float lod0Distance; public float lod1Distance; public float lod2Distance; } public struct SceneObject { public float loadPriority; public float3 worldPosition; public quaternion worldQuaternion; public float3 worldScale; public float3 aabbCenter; public float3 aabbExtents; public int prefabIndex; public int idInScene; }原先的数据在经过处理后,将重新组织成以下的形式。这样一来,我们就把原先以GameObject(prefab)组织的场景数据替换成了我们自己的场景数据,抛却了使用GameObject带来的额外开销,也方便我们按需加载/卸载相应的资源。 例如,不同层级的LOD仅需加载当前显示的LOD层级所需的资源,实际测试中发现,场景中60%以上的物体是LOD2,相比LOD1和LOD0,LOD2的体积无疑是很小的。而原生的LOD group需要将所有LOD层级引用的mesh都加载上来,按需加载LOD能节省至少一半的内存。不过需要额外注意的是,Unity3D导入FBX后,在AssetDatabase中,FBX本身是main asset,其中的mesh、animation clip等都是sub asset。 由于此时我们已经没有GameObject了,需要直接通过自定义数据结构索引mesh,而Unity3D在加载资源时仅能使用main asset路径加载,如AssetBundle.LoadAsync("xxxxxx.fbx")。但由于Unity3D的加载机制会将整个FBX所有的sub asset加载上来,所以无法达到按需加载的目的,因此需要实现新的接口实现精准加载一个sub asset,或者对FBX的mesh进行预处理,保存成新的asset。
运行时,scene streaming仍然以原先的逻辑对场景进行管理,只是当一个加载请求发起时,如果要加载的prefab不在预先处理的资源列表里,则还使用原先的加载、渲染流程,否则跳过原有的流程,等待新的流程进行管理,相关伪代码如下。需要注意的是,伪代码中的foreach/for仅作演示,实际使用中需要使用Job System对其进行并行化。 void MainTick() { ... // Scene streaming更新, 更新相机位置,要加载的区块等 SceneStreamingUpdate(); // loading流程 while (loadTasks.Count > 0) { var loadTask = loadTasks.Dequeue(); var prefabIndex = GetLoadingPrefabIndex(loadTask); // allSceneObjectPrefabIndex预处理时生成, 记录了所有SceneObject的prefabIndex if (allSceneObjectPrefabIndex.Contains(prefabIndex)) continue; // 原先的加载逻辑 LoadPrefab(prefabIndex); ... } // 新的加载流程 // 从SceneStreaming中获得当前加载的Section,将原先的GameObject信息转为SceneObject格式 foreach (var sectionIndex in loadingSectionIndices) { // sectionStaticObjects预处理时生成,记录了每个区块中的静态物体 foreach(SceneObject staticObj in sectionStaticObjects[sectionIndex]) { staticObjectInSections.Add(staticObj); } } // 对要加载的区块内的物体进行裁剪 foreach (SceneObject sceneObj in staticObjectInSections) { if(IsVisible()) visibleObjects.Add(sceneObj); } // 计算每个可见物体的LOD for (int i = 0; i |


【本文地址】